
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- gpt2
- 설명가능성
- Bert
- GPT
- MLOps
- 트랜스포머
- 지피티
- GPT-3
- 챗GPT
- 신뢰성
- DevOps
- word2vec
- Transformer
- Tokenization
- XAI
- ChatGPT
- cnn
- 케라스
- 챗지피티
- ML
- AI Fairness
- Ai
- 인공지능 신뢰성
- nlp
- 머신러닝
- trustworthiness
- 자연어
- fairness
- 딥러닝
- 인공지능
- Today
- Total
research notes
텍스트 분석(Text Analysis) 본문
1. 텍스트 분석 종류
- 텍스트 분류(Text Classification): Text categorization이라고도 하며 문서가 특정 분류 또는 카테고리에 속하는 것을 예측하는 기법
- 감성 분석(Sentiment Analysis): 텍스트에서 나타나는 감정/판단/믿음/의견/기분 등의 주관적인 요소를 분석하는 기법을 총칭
- 텍스트 요약(Summarization): 텍스트 내에서 중요한 주제나 중심 사상을 추출하는 기법이며 대표적으로 토픽 모델링(Topic Modeling)이 있다.
- 텍스트 군집화(Text Clustering)와 유사도 측정: 비슷한 유형의 문서에 대해 군집화를 수행하는 기법
2. 텍스트 분석 수행 프로세스
머신러닝 기반의 텍스트 분석은 다음과 같은 프로세스 순으로 수행
① 텍스트 사전 준비작업(텍스트 전처리): 텍스트를 피처로 만들기 전에 미리 클렌징, 대/소문자 변경, 특수문자 삭제 등의 클렌징 작업, 단어(Word) 등의 토큰화 작업, 의미 없는 단어(Stop word) 제거 작업, 어근 추출(Stemming/Lemmatization) 등의 텍스트 정규화 작업을 수행하는 것을 통칭
② 피처 벡터화/추출(Feature Vectorization): 사전 준비 작업으로 가공된 텍스트에서 피처를 추출하고 여기에 벡터 값을 할당한다. 대표적인 방법은 BOW(Bag of words)와 Word2Vec이 있으며 BOW는 대표적으로 Count 기반과 TF-IDF 기반 벡터화가 있다.
③ ML 모델 수립 및 학습/예측/평가: 피처 벡터화된 데이터 세트에 ML 모델을 적용해 학습/예측 및 평가를 수행

3. 텍스트 사전 준비 작업(텍스트 전처리) - 텍스트 정규화
텍스트 정규화는 텍스트를 머신러닝 알고리즘이나 NLP 애플리케이션에 입력 데이터로 사용하기 위해 클렌징, 어근화, 토큰화 등의 다양한 텍스트 데이터에 사전 작업을 수행하는 것을 의미한다.
a) 클렌징(Cleansing)
- 텍스트에서 분석에 오히려 방해가 되는 불필요한 문자, 기호 등을 사전에 제거하는 작업. 예를 들어 HTML, XML 태그나 특정 기호등을 사전에 제거
b) 스톱 워드 제거(Stop word)
- 스톱워드는 분석에 큰 의미가 없는 단어를 지칭하며, 예를 들어 영어에서 is, the, a, will 등 문장을 구성하는 필수 문법 요소지만 문맥적으로 큰 의미가 없는 단어가 이에 해당
c) 어간추출(Stemming)과 표제어 추출(Lemmatization)
- 텍스트 전처리의 목적은 말뭉치(Corpus)로부터 복잡성을 줄이는 것이며, 어간 추출과(Stemming) 표제어 추출은(Lemmatization) 문법적 또는 의미적으로 변화하는 단어의 원형을 찾아 말뭉치의 복잡성을 줄여주는 텍스트 정규화 기법이다.
- 영어를 예로 들면, 과거형, 현재 진행형, 미래형, 3인칭 단수 여부 등 많은 조건에 따라 원래 단어가 변하게 된다. play를 예로 들면 plays, played, playing 등과 같이 조건에 따라 다양하게 달라진다. 어간 추출과 표제어 추출의 목적은 단어의 원형을 찾는 것이다. 즉, played, plays, playing으로부터 play를 찾는 것이다.
- 두 기능 모두 원형 단어를 찾는다는 목적은 유사하지만, Lemmatizaition이 Stemmming보다 정교하며 의미론적인 기반에서 단어의 원형을 찾는다.
d) 토큰화(Tokenization)
- 토큰화의 유형은 문서에서 문장을 분리하는 '문장 토큰화'와 문장에서 단어를 토큰으로 분리하는 '단어 토큰화'로 나눌 수 있다.
- 문장 토큰화(Sentence tokenization): 문장의 마침표(.), 개행문자(\n) 등 문장의 마지막을 뜻하는 기호에 따라 분리
- 단어 토큰화(Word tokenization): 공백, 콤마(,), 마침표(.), 개행문자(\n) 등으로 단어를 분리
- 문장을 단어별로 하나씩 토큰화 할 경우 문맥적인 의미가 무시될 수 있으므로 이러한 문제를 해결하고자 n-gram(연속된 n개의 단어를 하나의 토큰화 단위로 분리하는 것)을 도입
- N-gram
- 문장을 개별 단어 별로 하나씩 토큰화 진행할 경우 문맥적인 의미가 무시 될 수도 있다. 따라서, 이러한 문제를 해결하기 위해 n-gram 방법이 고안되었다.
- n-gram은 연속된 n개의 단어를 하나의 토큰화 단위로 분리하는 것이다. n개 단어 크기 윈도우를 설정해 문장의 처음부터 오른쪽으로 이동하면서 토큰화를 수행한다.
- 예를 들어, 'Agent Smith knocks the door'를 2-gram(bigram)으로 만들 경우 (Agent, Smith), (Smith, knocks), ..., (the door)와 같이 연속적인 2개의 단어들을 순차적으로 이동하면서 단어들을 토큰화한다.
- N-gram
4. Bag of Words (BOW)
Bag of Words 모델은 문서가 가지는 모든 단어(Words)를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 모델이다. 단점으로 문맥 의미(Semantic Context) 반영 부족과 희소 행렬(Sparse Matrix) 문제가 있다.
- 문맥 의미 반영 부족 문제: BOW는 단어의 순서를 고려하지 않기 때문에 문장 내에서 단어의 문맥적인 의미가 무시된다.
- 희소행렬 문제: 매우 많은 문서에서 단어의 총 개수는 수만~수십만 개가 될 수 있는데, 하나의 문서에 있는 단어는 이 중 극히 일부분이므로 대부분의 데이터는 0으로 채워지게 된다. 이처럼 대규모의 칼럼으로 구성된 행렬에서 대부분의 값이 0으로 채워지는 행렬을 희소행렬이라고 하며 희소행렬은 일반적으로 ML알고리즘의 수행시간과 예측 성능을 떨어뜨린다.
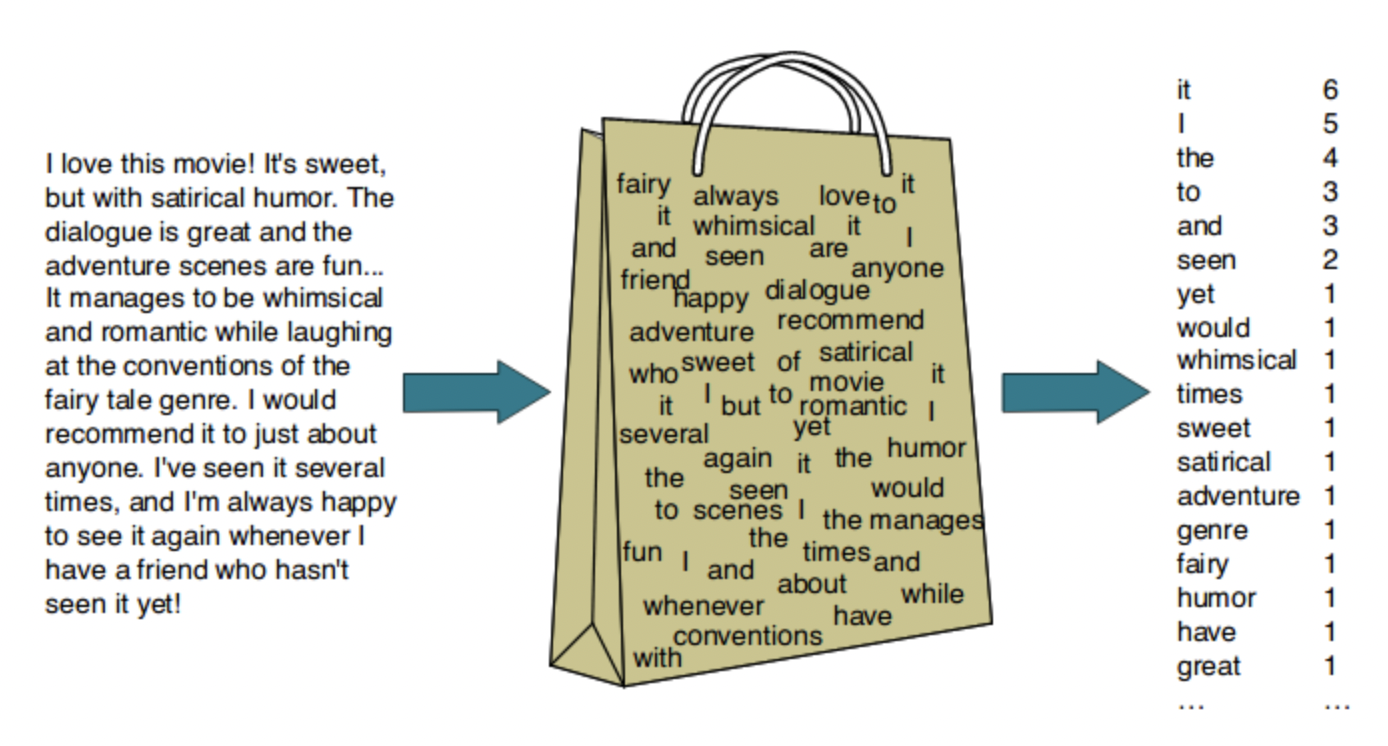
BOW의 피처 백터화는 두 가지 방식이 있다.
a) 카운트 기반의 백터화
- 단어 피처에 값을 부여할 때 각 문서에서 해당 단어가 나타나는 횟수, 즉 Count를 부여하는 경우를 카운트 벡터화라고 한다.
- 카운트 벡터화에서는 카운트 값이 높을수록 중요한 단어로 인식하며, 따라서 그 문서의 특징을 나타내기보다는 언어의 특성상 문장에서 자주 사용되는 단어에 높은 값을 부여한다.

b) TF-IDF(Term Frequency - Inverse Document Frequency) 기반의 벡터화
- 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 패널티를 주는 방식으로 값을 부여한다.
- 만일 어떤 문서에서 특정 단어가 자주 나타나면 그 단어는 해당 문서를 특정짓는 중요 단어일 수 있다. 그러나 해당 단어가 다른 문서에도 자주 나타나는 단어라면 해당 단어는 언어 특성상 범용적으로 사용될 가능성이 높다.


5. 문서 유사도 (코사인 유사도)
문서와 문서 간의 유사도 비교는 일반적으로 코사인 유사도(Cosine similarity)를 사용한다. 코사인 유사도는 벡터와 벡터간의 유사도를 비교할 때 벡터의 크기보다는 벡터의 상호 방향성이 얼마나 유사한지에 기반한다.
두 벡터의 사잇각에 따라서 상호 관계는 다음과 같이 유사하거나 관련이 없거나 아예 반대 관계가 될 수 있다.

또한, 두 벡터 A와 B의 코사인 유사도 값은 아래 식으로 구할 수 있다.

References:
[1] 파이썬 머신러닝 완벽가이드, 권철민, 위키북스
[2] 파이썬 머신러닝 완벽가이드, 권철민, 인프런 강좌
[3] https://dudeperf3ct.github.io/lstm/gru/nlp/2019/01/28/Force-of-LSTM-and-GRU/
[4] https://docs.sangyunlee.com/ml/untitled-1
[6] https://ko.wikipedia.org/wiki/%EC%BD%94%EC%82%AC%EC%9D%B8_%EC%9C%A0%EC%82%AC%EB%8F%84
[7] https://medium.com/geekculture/cosine-similarity-and-cosine-distance-48eed889a5c4
'GPT > 개념정의' 카테고리의 다른 글
| 트랜스포머(Transformer) (0) | 2022.04.24 |
|---|---|
| 서브워드 토크나이저(Subword Tokenizer) (0) | 2022.04.24 |
| 토큰화(Tokenization) (0) | 2022.04.22 |
| 워드임베딩(Word embedding)과 워드투벡터(Word2Vec) (0) | 2022.04.11 |
| 시퀸스-투-시퀸스 및 어텐션 매커니즘 (0) | 2022.02.17 |



