
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 챗GPT
- 머신러닝
- cnn
- nlp
- 인공지능
- XAI
- Tokenization
- Bert
- GPT-3
- 트랜스포머
- AI Fairness
- ChatGPT
- 케라스
- Transformer
- word2vec
- 신뢰성
- 설명가능성
- DevOps
- MLOps
- 인공지능 신뢰성
- 챗지피티
- 자연어
- ML
- trustworthiness
- gpt2
- fairness
- 딥러닝
- Ai
- GPT
- 지피티
- Today
- Total
research notes
순환 신경망 (RNN) 본문
*** 딥 러닝을 이용한 자연어 처리 입문 (위키북스) 내용 요약 ***
1. RNN 기초
- RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델이다.
- RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 갖고있다. (이 때 xt, yt는 벡터이다.)
- 메모리 셀이 출력층 방향 또는 다음 시점인 t+1의 자신에게 보내는 값을 은닉 상태(hidden state) 라고 한다. 다시 말해 t 시점의 메모리 셀은 t-1 시점의 메모리 셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력값으로 사용한다.
- RNN은 입력과 출력의 길이를 다르게 설계 할 수 있으므로 다양한 용도로 사용할 수 있다.


- RNN의 입력과 출력의 길이를 다르게 설계해 다양한 용도로 사용할 수 있음
- one-to-many: 이미지 캡셔닝 등
- many-to-one: 스팸 메일 분류, 감성분석 등
- many-to-many: 챗봇, 번역기 등

- RNN에 대한 수식

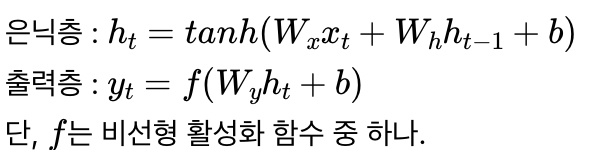
- 비선형 활성화 함수는 로지스틱 회귀, 시그모이드 함수, 소프트 맥스 등 다양하게 사용가능
# 아래의 코드는 가상의 코드(pseudocode)로 실제 동작하는 코드가 아님.
hidden_state_t = 0 # 초기 은닉 상태를 0(벡터)로 초기화
for input_t in input_length: # 각 시점마다 입력을 받는다.
output_t = tanh(input_t, hidden_state_t) # 각 시점에 대해서 입력과 은닉 상태를 가지고 연산
hidden_state_t = output_t # 계산 결과는 현재 시점의 은닉 상태가 된다.2. RNN Keras 구현
# 추가 인자를 사용할 때
model.add(SimpleRNN(hidden_units, input_shape=(timesteps, input_dim)))
# 다른 표기
model.add(SimpleRNN(hidden_units, input_length=M, input_dim=N))hidden_units = 은닉 상태의 크기를 정의. 메모리 셀이 다음 시점의 메모리 셀과 출력층으로 보내는 값의 크기(output_dim)와도 동일. RNN의 용량(capacity)을 늘린다고 보면 되며, 중소형 모델의 경우 보통 128, 256, 512, 1024 등의 값을 가진다.
timesteps = 입력 시퀀스의 길이(input_length)라고 표현하기도 함. 시점의 수.
input_dim = 입력의 크기.

RNN 층은 사용자의 설정에 따라 두 가지 종류의 출력을 내보낸다다.
- 메모리 셀의 최종 시점의 은닉 상태만을 리턴하고자 한다면 (batch_size, output_dim) 크기의 2D 텐서를 리턴
- 메모리 셀의 각 시점(time step)의 은닉 상태값들을 모아서 전체 시퀀스를 리턴하고자 한다면 (batch_size, timesteps, output_dim) 크기의 3D 텐서를 리턴
- 이는 RNN 층의 return_sequences 매개변수에 True를 설정하여 설정이 가능
- output_dim은 앞서 코드에서 정의한 hidden_units의 값으로 설정된다.
마지막 은닉 상태만 전달하도록 하면 다 대 일(many-to-one) 문제를 풀 수 있고, 모든 시점의 은닉 상태를 전달하도록 하면, 다음층에 RNN 은닉층이 하나 더 있는 경우이거나 다 대 다(many-to-many) 문제를 풀 수 있다.

3. 깊은 순환 신경망(Deep Recurrent Neural Network)
순환 신경망에서 은닉층이 1개 더 추가되어 은닉층이 2개인 깊은(deep) 순환 신경망이 가능하며, 첫번째 은닉층은 다음 은닉층이 존재하므로 return_sequences = True를 설정하여 모든 시점에 대한 은닉 상태 값을 다음 은닉층으로 전달

model = Sequential()
model.add(SimpleRNN(hidden_units, input_length=10, input_dim=5, return_sequences=True))
model.add(SimpleRNN(hidden_units, return_sequences=True))
4. 양방향 순환 신경망(Bidirectional Recurrent Neural Network)

RNN이 풀고자 하는 문제 중에서는 과거 시점의 입력 뿐만 아니라 미래 시점의 입력에 힌트가 있는 경우도 많다. 그래서 이전과 이후의 시점 모두를 고려해서 현재 시점의 예측을 더욱 정확하게 할 수 있도록 고안된 것이 양방향 RNN이다.
양방향 RNN은 하나의 출력값을 예측하기 위해 기본적으로 두 개의 메모리 셀을 사용. 첫번째 메모리 셀은 앞 시점의 은닉 상태(Forward States)를 전달받아 현재의 은닉 상태를 계산. 위의 그림에서는 주황색 메모리 셀에 해당. 두번째 메모리 셀은 앞 시점의 은닉 상태가 아니라 뒤 시점의 은닉 상태(Backward States) 를 전달 받아 현재의 은닉 상태를 계산. 입력 시퀀스를 반대 방향으로 읽는 것이다. 위의 그림에서는 초록색 메모리 셀에 해당. 그리고 이 두 개의 값 모두가 현재 시점의 출력층에서 출력값을 예측하기 위해 사용된다.
from tensorflow.keras.layers import Bidirectional
timesteps = 10
input_dim = 5
model = Sequential()
model.add(Bidirectional(SimpleRNN(hidden_units, return_sequences=True), input_shape=(timesteps, input_dim)))5. 바닐라 RNN
바닐라 RNN은 비교적 짧은 시퀀스(sequence)에 대해서만 효과를 보이는 단점이 있다. 바닐라 RNN의 시점(time step)이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생하는데, 이를 장기 의존성 문제(the problem of Long-Term Dependencies)라고 한다.

6. LSTM과 GRU
LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정한다. 즉. LSTM은 은닉 상태(hidden state)를 계산하는 식이 전통적인 RNN보다 조금 더 복잡해졌으며 셀 상태(cell state)라는 값을 추가 반면, GRU에서는 업데이트 게이트와 리셋 게이트 두 가지 게이트만이 존재하며, GRU는 LSTM보다 학습 속도가 빠르다고 알려져있지만 여러 평가에서 GRU는 LSTM과 비슷한 성능을 보인다고 알려져 있음
7. RNN을 이용한 텍스트 분류
텍스트 분류는 RNN의 다 대 일(many-to-one) 문제에 속한다. 즉, 텍스트 분류는 모든 시점(time steps)에 대해서 입력을 받지만 최종 시점의 RNN 셀만 은닉상태를 출력하고, 이것이 출력층으로 가서 활성화 함수를 통해 정답을 고르는 문제가 된다.

References:
[1] https://wikidocs.net/22886, 위키독스, 딥러닝을 이용한 자연어처리 입문
'자연어 > Basic' 카테고리의 다른 글
| 케라스 임베딩 층(Keras embedding layer) (0) | 2022.04.13 |
|---|---|
| NLP를 위한 합성곱 신경망(Convolution Neural Network) (0) | 2022.04.12 |

