
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- gpt2
- DevOps
- word2vec
- 딥러닝
- 인공지능
- Transformer
- AI Fairness
- 인공지능 신뢰성
- 설명가능성
- 케라스
- 신뢰성
- 지피티
- XAI
- trustworthiness
- 트랜스포머
- fairness
- 챗지피티
- 자연어
- GPT-3
- Bert
- 머신러닝
- GPT
- Ai
- nlp
- 챗GPT
- ChatGPT
- cnn
- ML
- Tokenization
- MLOps
- Today
- Total
research notes
Statistical Parity Difference (SPD) 본문
SPD는 그룹 공정성(Group fairness) 평가 알고리즘 중 하나이며 그룹 공정성은 특권 집단의(privileged group) 구성과 비특권 집단의(unprivileged group) 구성을 평균적으로 비교하는 것이다.
SPD는 그룹 공정성을 측정하기 위한 매트릭이며 특권 그룹(𝑍 = priv; white)과 비특권 그룹(𝑍 = unpr; black) 사이의 유리한 레이블(favorable label) 𝑃(𝑦̂(𝑋) = fav)(특별한 보살핌을 받는 비율)의 선택 비율의 차이를 계산하여 불평등 효과(disparate impact)를 정량화한다.

SPD의 값이 0이면 비특권 그룹(흑인)과 특권 그룹(백인)의 구성원이 동일한 비율로 favorable label로 선택되어 공정한 상황으로 간주된다. 또한, 음수 값은 비특권 그룹이 불리한 위치에 있음을 나타내고 양수 값은 특권 그룹이 불리한 위치에 있음을 나타낸다.
아래 그림 은 SPD 계산의 예를 도식화 한 것이다. 비특혜 집단의 3명이 favaroable lable(간호를 관리를 받음) 로 예측되고 7명은 unfavorable label(간호 관리를 받지 않음)로 예측된다. 특권 그룹의 4명은 호의적 레이블로 예측되고 6명은 비호의적 레이블로 예측됩니다. 비특권 그룹의 선택 비율은 3/10, 특권 그룹의 선택 비율은 4/10입니다. 차이, 통계적 패리티 차이는 -0.1이다.

Disparate impact는 비율을 척도로도 계산할 수 있다.

여기서 값이 1이면 공정함, 1보다 작으면 비특권, 1보다 크면 특권층에게 불리하다.
Disparate impact ratio는 relative risk ratio 또는 adverse impact ratio라고도 불린다.
고용과 같은 일부 적용 영역에서 이질적인 영향 비율 값이 0.8 미만이면 불공정한 것으로 간주되고 0.8보다 큰 값은 공정한 것으로 간주된다(4/5 규칙).
미국의 고용평등위원회(Equal Employment Opportunity Commission)는 차별이 있었을 것이라고 판단하는 통계적 불균형의 정도를 4/5규칙으로 정하고 있으며, 미국 법원에서는 이에 의한 차별입증을 법적으로 인정하고 있다. 4/5규칙은 어떠한 고용상의 기준에 의해 소수 집단의 비율이 다수 집단의 비율이 4/5(80%)미만일 경우, 그 기준은 소수 집단에게 불리한 영향을 주어 ‘불평등 효과(adverse impact)를 야기한 것이고, 따라서 그 기준은 차별적이라고 판단하는 것이다. 예를 들어 여성은 승진대상자 12명 중에서 3명만이 승진한데 반해 남성은 25명 중 15명이 승진했다면 여성의 승진비율 25%는 남성 승진 비율 60%의 4/5인 48%에 미치지 못하기 때문에 차별이라고 판단하는 것이다. 4/5규칙에 의해 일단 통계적으로 차별 혐의가 입증되면, 고용주는 그 고용상의 기준이 차별적인 것이 아니라는 점을 입증해야 한다.
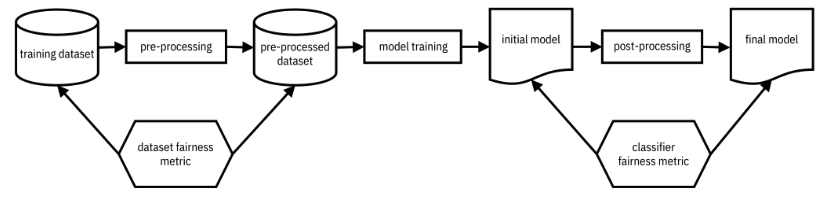
𝑦̂(𝑋) 를 𝑌 로 대체하여 모델 예측 대신 훈련 데이터에서 통계적 패리티 차이와 이질적인 영향 비율을 정의할 수도 있다. 따라서 아래 그림과 같이 모델 학습 전 데이터 세트에서 데이터 세트 공정성 메트릭으로, (2) 모델 학습 후 학습된 분류기에 대해 분류기 공정성 메트릭으로 측정 및 테스트할 수 있다.
References:
[1] Trustworthy Machine Learning by Kush R. Varshney