
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- GPT
- nlp
- 설명가능성
- Tokenization
- 머신러닝
- 챗지피티
- Ai
- 챗GPT
- 트랜스포머
- ML
- GPT-3
- 딥러닝
- MLOps
- XAI
- gpt2
- cnn
- 신뢰성
- Transformer
- AI Fairness
- 인공지능 신뢰성
- ChatGPT
- DevOps
- 인공지능
- 지피티
- 케라스
- trustworthiness
- 자연어
- fairness
- Bert
- word2vec
- Today
- Total
research notes
사이킷런 정리 본문
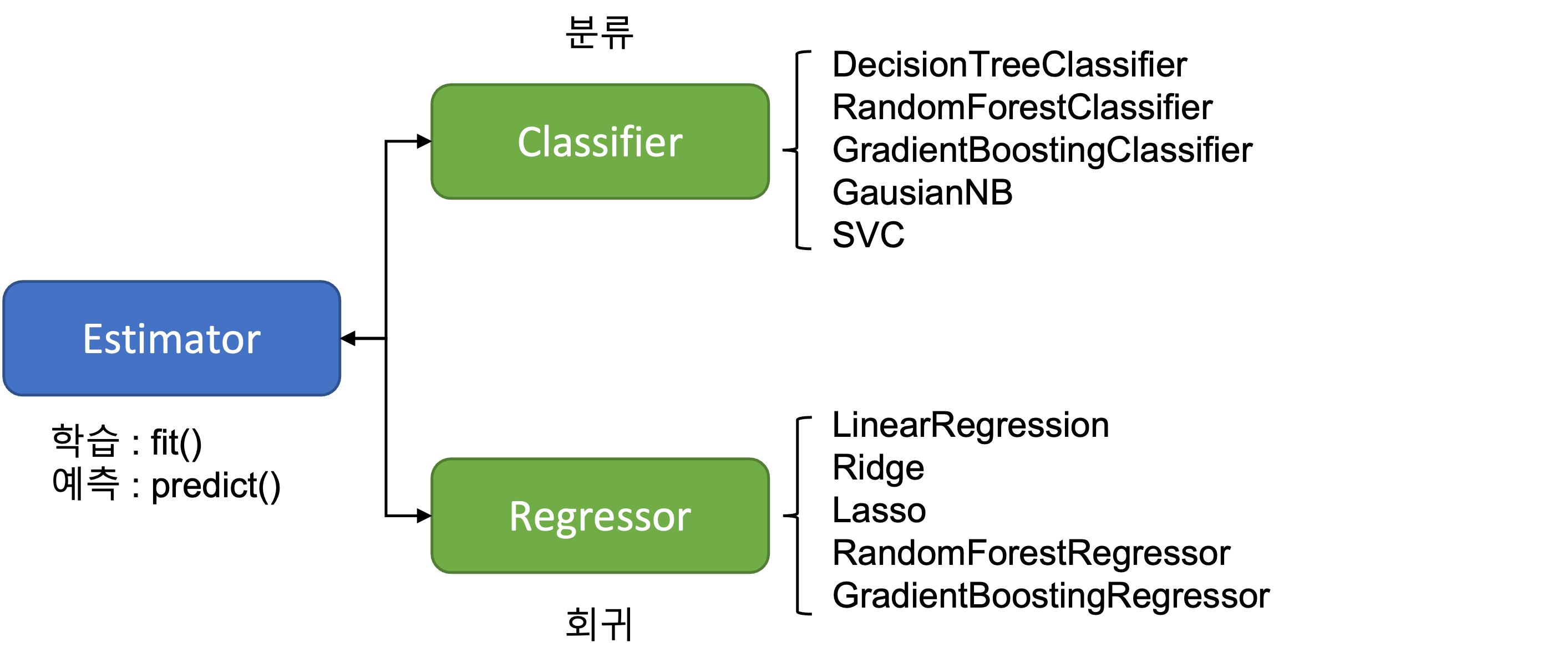
1. Estimator 이해 및 fit(), predict() 메서드
사이킷런은 매우 많은 유형의 Classifier와 Regressor 클래스를 제공한다. 이들 Classifier와 Regressor를 합쳐서 Estimator 클래스라고 부른다. 즉, 지도학습의 모든 알고리즘을 구현한 클래스를 통칭해서 Estimator라고 부른다.
2. 교차검증
① 홀드아웃 교차검증(holdout cross-validation)
데이터를 학습 데이터 세트와 테스트 데이터 세트 두 개로 나누는 것이며, 보통 데이터의 2/3을 학습 데이터 세트로 사용하고 1/3을 테스트 세트로 사용한다.

② k-겹 교차검증(k-fold cross-validation)
가장 보편적으로 사용되는 교차검증 기법으로 먼저 k개의 데이터 폴드 세트를 만들어서 k번 만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행한다.

③ Stratified K 폴드:
- 불균형한(imbalanced) 분포를 가진 레이블(결정 클래스) 데이터 집합을 위한 K 폴드 방식
- Stratified K 폴드는 원본 데이터의 레이블 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습과 검증 데이터 세트를 분배
- 비율을 고려하지 않을 경우 특정 레이블 값이 특정 학습/테스트 데이터 세트에는 상대적으로 많이 들어있는 반면, 다른 학습/테스트 데이터 세트에는 그렇지 못한 결과가 발생할 수 있음
④ cross_val_score():
- cross_val_score() API는 내부에서 Estimator를 학습(fit), 예측(predict), 평가(evaluation) 시켜주므로 간단하게 교차검증을 수행할 수 있다.
- cross_val_score()는 classifier가 입력되면 Stratified K 폴드 방식으로 레이블 값의 분포에 따라 학습 및 검증 세트를 분할
from sklearn.model_selection import cross_val_score
scores = cross_val_score(dt_clf, X_titanic_df, y_titanic_df, cv=5)
for iter_count, accuracy in enumerate(scores):
print("교차 검증 {0} 정확도: {1:.4f}".format(iter_count, accuracy))
print("평균 정확도: {0:.4f}".format(np.mean(scores)))⑤ GridSearchCV:
- 사이킷런은 GridSearchCV API를 활용해 Classifier나 Regressor와 같은 알고리즘에 사용되는 하이퍼파라미터를 순차적으로 입력하면서 편리하게 최적의 파라미터를 도출할 수 있는 방안을 제공
from sklearn.model_selection import GridSearchCV
parameters = {'max_depth':[2,3,5,10],
'min_samples_split':[2,3,5], 'min_samples_leaf':[1,5,8]}
grid_dclf = GridSearchCV(dt_clf, param_grid=parameters, scoring='accuracy', cv=5)
grid_dclf.fit(X_train, y_train)3. 데이터 전처리
- 머신러닝을 위한 대표적인 인코딩 방식은 레이블 인코딩(Label encoding)과 원-핫 인코딩(One-hot encoding)이 있다.
- 레이블 인코딩: 상품 데이터의 상품 구분이 TV, 냉장고, 전자레인지, 컴퓨터, 선풍기, 믹서 값으로 돼 있다면 TV:1, 냉장고: 2, 전자레인지: 3, 컴퓨터: 4, 선풍기: 5, 믹서: 6과 같은 숫자형 값으로 변환하는 것이다.
- 원-핫 인코딩: 피처 값의 유형에 따라 고유값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방식

References:
[1] 파이썬 머신러닝 완벽가이드, 권철민, 위키북스
[2] https://skasha.tistory.com/81
[3] https://www.holehouse.org/mlclass/04_Linear_Regression_with_multiple_variables.html
'머신러닝 > ML basic' 카테고리의 다른 글
| K-평균 알고리즘(K-Means Clustering) (0) | 2022.02.11 |
|---|---|
| Validation data set는 모델 학습에 사용이 되는가? (0) | 2022.02.05 |
| 규제 (Regularization) (0) | 2022.01.31 |
| 성능평가지표 (Evaluation Metric) (0) | 2022.01.30 |
| Numpy/Pandas 정리 (0) | 2022.01.28 |



