
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 지피티
- fairness
- GPT-3
- 챗GPT
- Tokenization
- 트랜스포머
- 설명가능성
- trustworthiness
- 신뢰성
- nlp
- Bert
- MLOps
- 자연어
- 머신러닝
- 케라스
- cnn
- ML
- 챗지피티
- 인공지능
- Transformer
- AI Fairness
- gpt2
- word2vec
- 딥러닝
- ChatGPT
- GPT
- 인공지능 신뢰성
- DevOps
- Ai
- XAI
- Today
- Total
research notes
피처 스케일링(Feature scaling) 본문
데이터 세트의 각 feature 값 범위가 크게 다를 경우 학습시에 손실함수가(loss function) 제대로 동작하지 않을 수 있으며, 경사하강법이(gradient descent) 피쳐 스케일링을 사용하지 않을 때보다 훨씬 빠르게 수렴하기 때문에 피쳐 스케일링 사용이 권고된다.
- e.g.) x1 = size (0-2000 feet), x2 = number of bedrooms (1-5)
- 해당 feature 값의 범위에서 생성된 손실함수의 등고선을 분석해보면 큰 범위 차이로 인해 세로로 크고 얇은 모양을 나타낸다.
- 이런 종류의 손실함수에서 경사하강법을 실행하면 전역 최소값을(global minimum) 찾는 데 오랜 시간이 걸릴 수 있다.

*** 표준화 및 정규화 ***
표준화(Standardization): 표준화는 데이터의 피처 각각을 평균이 0이고 분산이 1인 가우시안 정규분포를 가진 값으로 변환하는 것을 의미
StandardScaler: 평균이(μ) 0이고 분산이(σ) 1인 정규 분포 형태로 변환
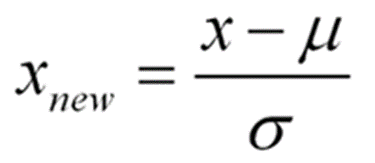
정규화(Normalization): 정규화는 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념
MinMaxScaler: 데이터 값을 0과 1사이의 범위 값으로 변환. 음수 값이 있으면 -1에서 1값으로변환

*** 학습 데이터와 테스트 데이터의 스케일링 변환시 유의점 ***
fit(): 데이터 변환을 위한 기준 정보 설정(ex. 데이터 세트의 최댓값/최솟값 설정 등)
transform(): fit()에서 설정된 기준 정보를 기반으로 데이터 변환
학습 데이터로 fit()이 적용된 스케일링 기준 정보를 그대로 테스트 데이터에 적용해야 하며, 그렇지 않고 테스트 데이터로 다시 새로운 스케일링 기준 정보를 만들게 되면 학습데이터와 테스트 데이터의 스케일링 기준 정보가 서로 달라지기 때문에 올바른 결과 도출을 하지 못할 수도 있음
=> 가능하다면 전체 데이터의 스케일링 변환을 적용한 뒤 학습과 테스트 데이터로 분리
=> 여의치 않다면 테스트 데이터 변환 시에는 fit()이나 fit_transform()을 적용하지 않고 학습 데이터로 이미 fit()된 Scaler 객체를 이용해 transform() 수행
=> 위의 유의사항은 사이킷런 기반의 PCA와 같은 차원축소 변환, 텍스트의 피처 벡터화 변환 작업 시에도 동일하게 적용
References:
[1] 파이썬 머신러닝 완벽가이드, 권철민, 위키북스
[2] https://towardsdatascience.com/scale-standardize-or-normalize-with-scikit-learn-6ccc7d176a02
'머신러닝 > ML basic' 카테고리의 다른 글
| 결정트리 (Decision Tree) (0) | 2022.03.28 |
|---|---|
| PCA (Principal Component Analysis) (0) | 2022.02.19 |
| K-평균 알고리즘(K-Means Clustering) (0) | 2022.02.11 |
| Validation data set는 모델 학습에 사용이 되는가? (0) | 2022.02.05 |
| 규제 (Regularization) (0) | 2022.01.31 |



