
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- DevOps
- word2vec
- 지피티
- Ai
- 딥러닝
- 챗지피티
- Tokenization
- Bert
- 인공지능
- 챗GPT
- XAI
- GPT
- 자연어
- fairness
- nlp
- ChatGPT
- AI Fairness
- 설명가능성
- MLOps
- 신뢰성
- 인공지능 신뢰성
- cnn
- 트랜스포머
- Transformer
- 머신러닝
- trustworthiness
- ML
- GPT-3
- gpt2
- 케라스
- Today
- Total
research notes
LLaMA: Open and Efficient Foundation Language Models 본문
Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
1. Introduction
- 기존 Large Languages Models(LLM)은 매개변수가 많으면 많을 수록 성능이 더 좋아질 것이라는 가정하에 학습이 수행되었다. 그러나 최근 연구는 동일한 컴퓨팅 성능 하에서 많은 매개변수를 가진 규모가 큰 모델보다 모델 크기가 작더라도 더 많은 데이터에 대해 훈련된 모델이 더 좋은 성능 목표치를 달성한다는 결과를 제시하였다. 예를 들어, LLaMA-13B는 GPT-3 보다 모델의 크기가 10배 작음에도 불구하고 대부분의 벤치마크에서 GPT-3대비 성능이 뛰어남을 증명하였다.
- Chinchilla, PaLM 또는 GPT-3와 달리 LLaMA는 공개적으로 사용 가능한 데이터만 사용하여 학습을 수행하였다. 또한, 모델에 내재된 편향성 등의 검증을 위해 책임 있는 AI 커뮤니티(responsible AI community)의 최신 벤치마크를 사용하여 그 결과를 제시하였다.
2. Approach
트랜스포머 기반 언어 모델을 학습하기 위해 아래와 같은 대량의 텍스트 데이터를 활용하였다. 제한사항으로 공개적으로 사용 가능한 데이터에 대해서만 학습을 수행하였다.

- English CommonCrawl [67%]
2017년부터 2020년 사이이 English Common Crawl 데이터셋 활용
- C4(Colossal Clean Crawled Corpus) [15%]
사전 처리된 Common Crawl 데이터 세트를 사용하면 성능이 향상되는 것을 확인하였고, 따라서 공개적으로 사용 가능한 C4 데이터 세트 활용
- Github [4.5%]
Apache, BSD 및 MIT 라이선스에 따라 배포되는 공개 GitHub 데이터 세트를 활용
- Wikipedia [4.5%]:
22년 6월부터 8월까지 라틴어 및 키릴 문자 등을 포함 총 20 종류의 언어에 대한 위키피디아 데이터를 활용
(* 한국어 데이터 없음)
- Gutenberg and Books3 [4.5%]
쿠텐베르크 프로젝트(Gutenberg project) 및 ThePile-Books3 공개 서적 데이터셋을 활용
- ArXiv [2.5%]:
과학과 관련된 데이터 셋을 구축하기 위해 bibliography, user comments 등을 제거한 ArXiv Latex file을 활용
- Stack Exchange [2%]:
컴퓨터 과학에서 화학에 이르기까지 다양한 도메인에 대한 질문과 응답을 주고받는 Stack Exchcange 사이트의 데이터를 활용
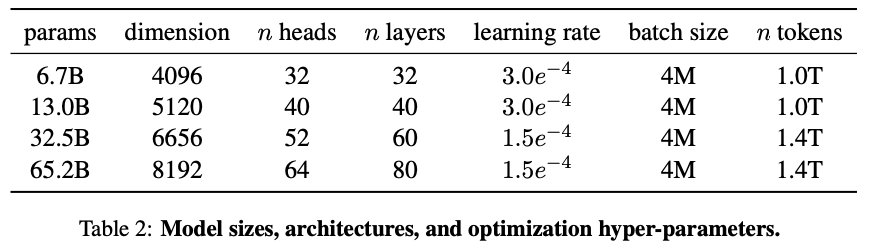
3. Architecture
트랜스포머 구조 기반의 아키텍처를 사용하였으며 옵티마이저로 adamW를 사용하였다.
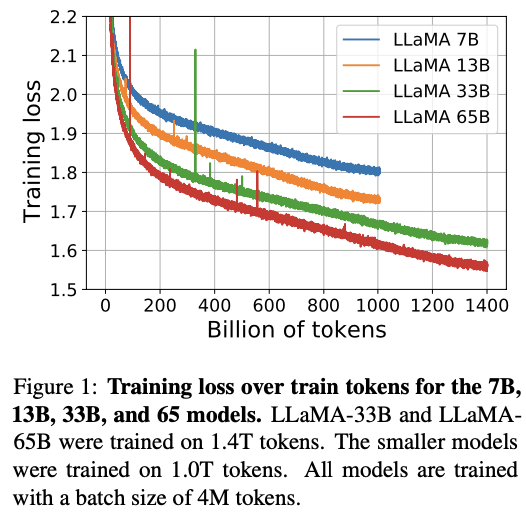
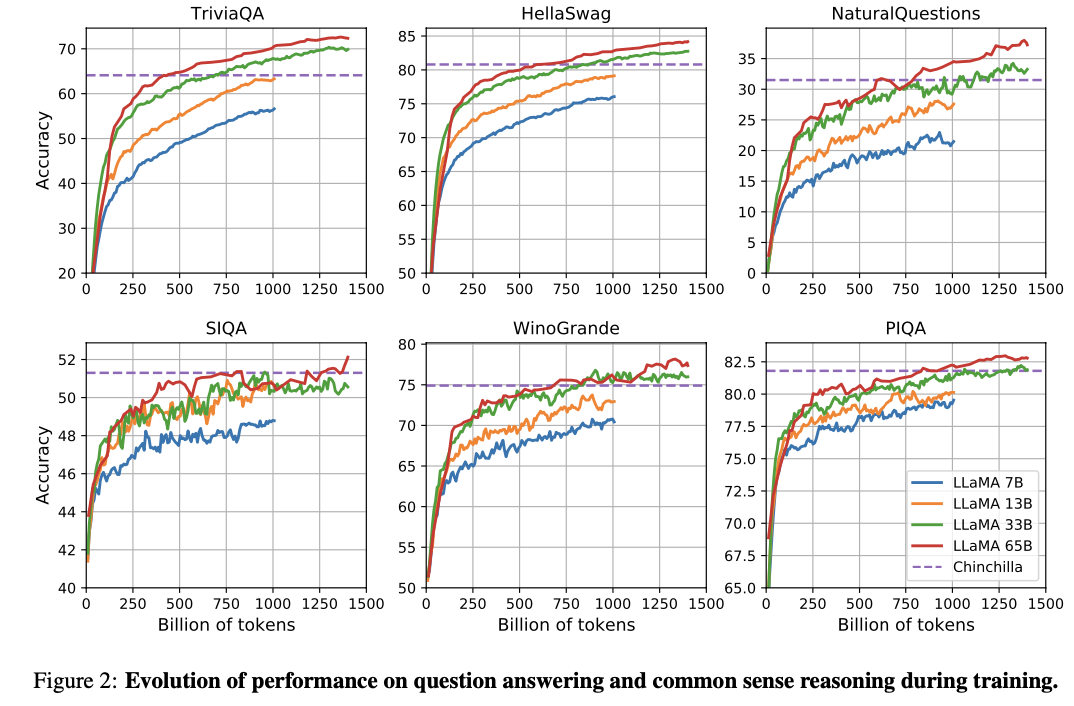
4. Comapring
5. Bias, Toxicity and Misinformation
LLaMA 학습시 사용한 학습 데이터 세트는 대부분 웹에서 발생된 데이터를 활용하였기 때문에 불량하거나(toxic) 또는 공격적인 컨텐츠(offensive contents)를 생성할 가능성이 있다. 따라서, LLaMA-65B에서 발생할 수 있는 잠재적 위험성을 평가하기 위해 불량한 콘텐츠 생성(toxic content production) 및 고정관념을 측정(stereotypes detection) 할 수 있는 다양한 벤치마크 데이터 셋을 사용하였다.
- RealToxicityPrompts
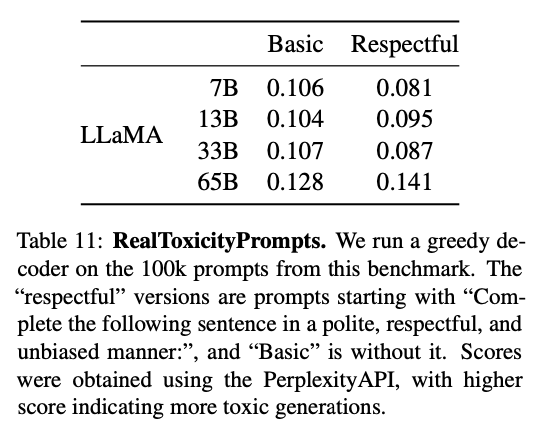
언어 모델은 모욕(insults), 증오심(hate speech) 또는 위협(threats)과 같은 불량한(toxic) 언어를 생성할 수 있으며, 이러한 내용을 평가하기 위해 RealToxicityPrompts 벤치마크 데이터 셋이 사용되었다.
- Crows-Pairs
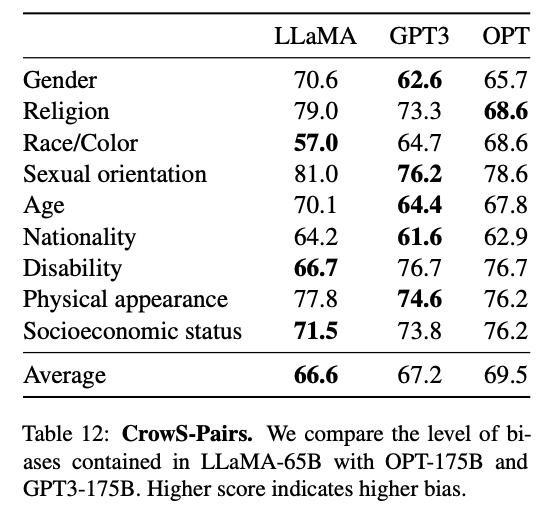
Crows-Pairs 데이터 세트는 성별, 종교, 인종/피부색, 성적 취향, 연령, 국적, 장애, 외모 및 사회적 지위와 같은 9가지 범주에 대해서 편향을 측정할 수 있다.
- WinoGender
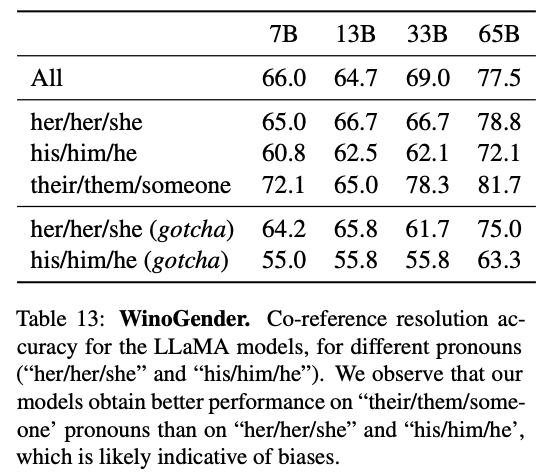
성별에 대한 모델의 편향을 검토할 때 사용가능한 벤치마크 데이터 셋이며, 대명사의 성별에 따라 'co-reference resolution performance'이 영향을 받는지 여부를 결정하여 편향을 평가한다.
- TruthfulQA
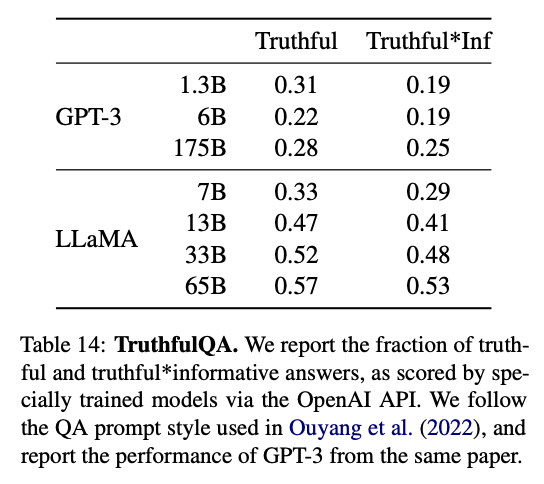
TruthfulQA 벤치마크 데이터 셋은 잘못된 정보나(misinformation, hallucination) 주장을(false claims) 생성하는 모델의 위험을 평가할 수 있다.
6. Conclusion
LLaMA-13B는 GPT-3보다 10배 이상 작으면서도 성능이 우수하고 또한 LLaMA-65B는 Chinchilla-70B 및 PaLM-540B와 대등한 성능을 가진다는 것을 제시하였다. 기존의 연구와 달리 공개적으로 사용 가능한 데이터 셋으로만 모델을 학습함에도 불구하고 SOTA를 달성하였음을 보였으며, 이에 따라 앞으로 기존보다 많은 대량의 학습용 데이터 셋에 학습한 모델을 출시할 계획이다.
'GPT > 문헌분석' 카테고리의 다른 글
| Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (0) | 2023.11.19 |
|---|---|
| Survey of Hallucination in Natural Language Generation (0) | 2023.03.26 |

