
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 설명가능성
- 케라스
- Ai
- DevOps
- 지피티
- trustworthiness
- AI Fairness
- ChatGPT
- XAI
- fairness
- 딥러닝
- gpt2
- 머신러닝
- 챗지피티
- Transformer
- ML
- 인공지능
- GPT-3
- 인공지능 신뢰성
- MLOps
- Bert
- 트랜스포머
- word2vec
- 자연어
- 챗GPT
- Tokenization
- GPT
- cnn
- 신뢰성
- nlp
- Today
- Total
research notes
Survey of Hallucination in Natural Language Generation 본문
Ji, Ziwei, et al. "Survey of hallucination in natural language generation." ACM Computing Surveys 55.12 (2023): 1-38
들어가며
현재 자연어 생성(Natural Language Generation, NLG)에서 발생하는 할루시네이션(Hallucination) 문제를 해결하기 위해 많은 연구자들이 관련 측정(metric) 및 완화(mitigation) 방법을 제시하고 있지만 아직 종합적으로 검토되지 않았다. 따라서, 본 기술보고서는 NLG의 할루시네이션 문제에 대한 연구 현황(progress) 및 도전 과제(challenges)에 대한 종합적인 개요를 제공하는 것을 목적으로 작성되었다.
1. Introduction
최근 딥러닝 기술의 발전에 힘입어(특히, Transformer 기반 모델인 BERT, GPT-3 등) 자연어 생성(NLG) 기술은 급속한 기술 발전과 동시에 한계와 잠재적 위험에 대한 관심도 또한 증가하고 있다. 예를 들어 자연어 생성 모델이 종종 무의미한(nonsensical) 텍스트를 생성하거나 제공된 입력에 충실하지(untruithful) 않은 경우가 있다는 것이 발견되었는데 연구자들은 이러한 불필요한 생성 현상을 할루시네이션이라고 부르기 시작했다.
기존의 연구들은 텍스트 요약 및 번역과 같은 특정 작업에만 초점을 맞추고 있다. 따라서 본 보고서에서는 자연어 생성(NLG)에서 할루시네이션 문제에 대한 연구 현황과 도전 과제에 대한 조사를 수행하였다.
2. Definiton
자연어 처리에서 할루시네이션은 제공된 소스 콘텐츠(provided source contentes)에 충실하지(unfaithful) 않거나 무의미하게(nonsensical) 생성된 콘텐츠를 의미하며 가장 포괄적이고 표준적인 정의이다. 그러나, 자연어 생성(NLG)에서는 각 태스크 마다 정의에 대한 차이가 존재한다.
2.1 Categorization
환각에는 주로 내재적 환각(Intrinsic Hallucinations)과 외재적 환각(Extrinsic Hallucinations) 두 가지 유형이 존재한다.

1) Intrinsic Hallucinations: 생성된 결과물이 원본 내용과 모순되는(contradicts) 경우
ex) 위 표1의 Abstractive Summarization 작업의 결과물로 요약된 "The first Ebola vaccine was apporoved in 2021(첫 에볼라 백신은 2021년에 승인 되었습니다)"는 원본 내용인 "The first vaccine for Ebola was approved by the FDA in 2019 in the US(첫 에볼라 백신은 FDA에 의해 2019년에 승인 되었습니다)"와 모순된다.
2) Extrinsic Hallucinations: 원본 컨텐츠에서 확인할 수 없는 생성된 출력(즉, 출력 결과가 원본 컨텐츠와 관련이 있지도 않고 그렇다고 원본 컨텐츠에 모순이 되지 않는 경우)
ex) 단순 정의만 보면 이해하기 어려울 수 있으므로 예를 참고하자.
표 1의 Abstractive Summarization 작업에서 "China has already started clinical trials of the COVID-19 vaccine(중국은 이미 COVID-19 백신의 임상 시험을 시작했다)."라는 정보는 원본에 언급되어 있지 않다. 즉, 생성된 결과에 대한 증거(evidence)를 원본에서 찾을 수 없는데 그렇다고 그 결과가 잘못되었다고 주장할 수도 없다. 이유는 Extrinsicn Hallucinations이라고해서 항상 잘못된 것은 아니며그 결과가 원본에는 없더라도 정확한 외부 정보에서 비롯될 수 있기 때문이다.
2.2 Terminology Clarification
Halllucination - 제공된 소스 콘텐츠(provided source contentes)에 충실하지(unfaithful) 않거나 무의미하게(nonsensical) 생성된 콘텐츠를 의미
Faithfulness - 제공된 원천에 대해 일관되고 진실한 것으로 남아있음을 의미. 이 단어에 대한 반의어는 할루시네이션이다.
3. Metrics measuring hallucination
최근 다양한 연구에서 텍스트 관련 태스크 품질을(quality of writing) 측정하는 데 사용되는 대부분의 전통적인 지표들이(ex. ROUGE, BLEU, METEOR 등) 할루시네이션 수준을 정량화하는 데 적합하지 않음을 보여주었다. 따라서, 할루시네이션을 정량화하는 효과적인 지표를 정의하기 위한 연구들이 활발하게 진행되고 있다.
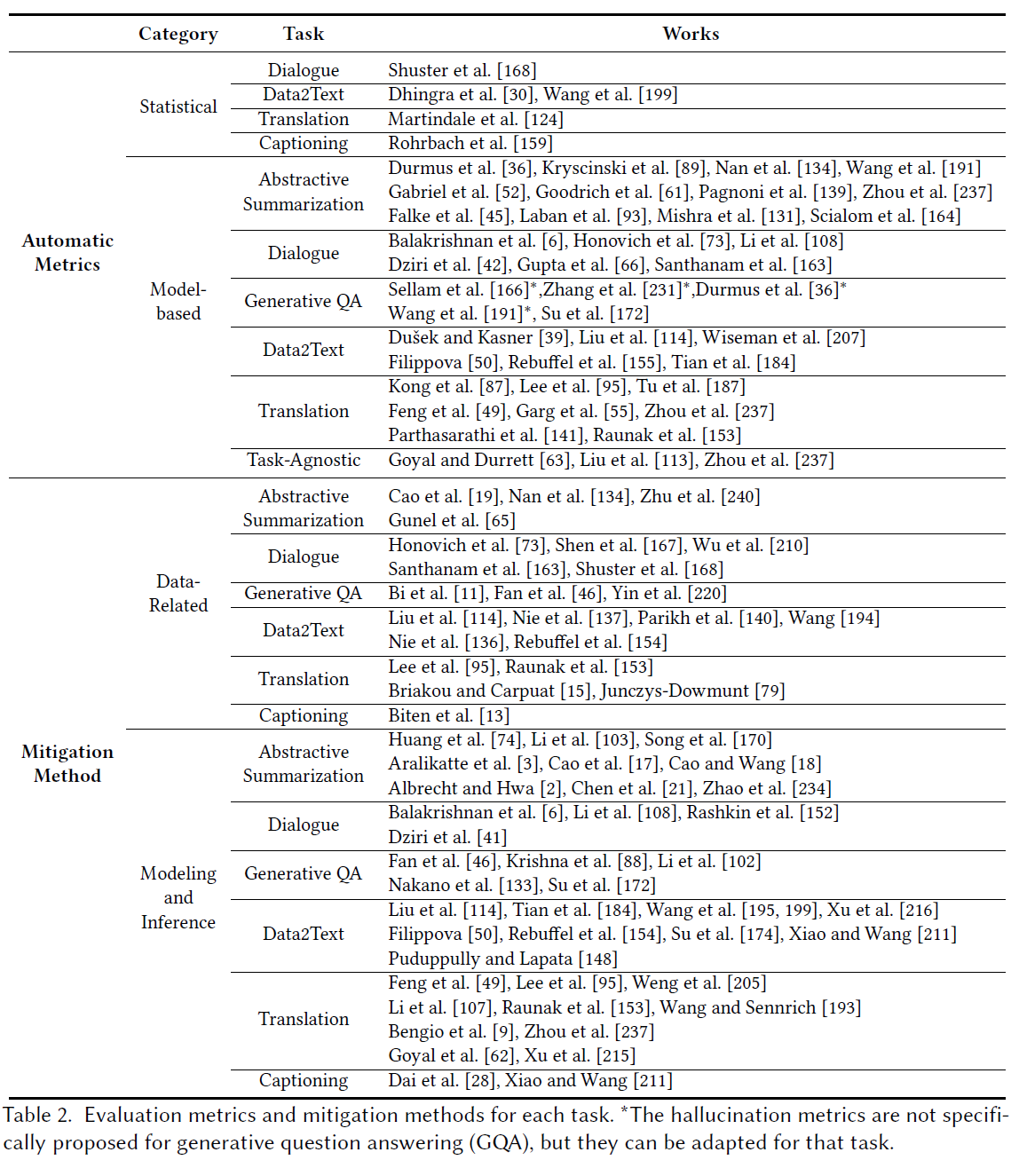
3.1 Statical Metric
가장 간단한 접근 방식 중 하나는 어휘(lexical) 특성(n-gram)을 활용하여, 생성된 텍스트와 참조 텍스트 간의 정보 중복(overlap) 및 모순(cotradictions)을 계산하는 것이다. 불일치 횟수가 높을수록 충실도가(faithfulness) 낮아지고 그 결과 할루시네이션 점수가 높아진다. PARENT, PARENT-T, BVSS와 같은 방법이 제안되었다. (*논문에서는 주로 Data2Text 지표에 대한 내용을 기반으로 서술하고 있음)
3.2 Model-based Metric
모델 기반 지표는 생성된 텍스트에서 할루시네이션 정도를(원문과 생성된 텍스트 사이의 불일치) 측정하기 위해 신경망 모델을 활용한다.
1) Information Extraction(IE)-based:
IE 기반 지표들은 텍스트를 간단한 튜플 형식(예: 주체, 관계, 객체)으로 나타내주는 IE 모델을 사용하여 원본(source) 및 참조(reference) 텍스트에서 추출한 튜플을 비교하여 검증한다. 여기서 IE 모델은 검증이 필요한 '사실'을 식별하고 추출하는 역할을 한다. 이 방식으로 검증 단계에서 필요 없는 단어(ex: stopwords, 접속사 등)는 포함되지 않는다.
ex) Brad Pitt was born in 1961(ground text) / Brad Pitt was born in 1963(genrated text)
IE 모델 사용 → (Brad Pitt, born-in, 1963) / (Brad Pitt, born-in, 1961) → 1963과 1961을 비교하여 할루시네이션 여부를 평가할 수 있다.
2) QA-based:
원본과 결과 사이의 지식 겹침이나 일관성을 함축적으로 측정한다. 이는 결과가 원본과 사실적으로 일관된다면 동일한 질문에서 비슷한 답변이 생성될 것이라는 직관에 기반한다. 생성된 텍스트의 충실도를 측정하는 QA 기반 지표는 세 부분으로 구성된다. 첫째, 생성된 텍스트가 주어지면, 질문 생성(QG) 모델이 질문-답변 쌍을 생성한다. 둘째, 질문 응답(QA) 모델이 지식이 포함된 기준 소스 텍스트를 참조로 하여 생성된 질문에 답변한다. 마지막으로, 환영 점수는 해당 답변의 유사성을 기반으로 계산된다.
3) Natural Language Inference(NLI) Metrics:
할루시네이션 문제가 주목을 받던 초기에는 이를 평가하기 위한 데이터 셋이 많이 없었다. 따라서 이에 대한 대안으로 자연어 추론(NLI)* 방법을 사용하여 할루시네이션을 평가하였다. NLI는 '가설(hypothesis)'과 '전제(premise)'가 주어졌을 때 함의(entailment), 모순(contradiction) 또는 중립(neutral)인지 여부를 결정하는 작업이다. NLI 기반 지표는 원본과 생성된 텍스트 간의 entailment probability, 즉 생성된 텍스트가 원본을 함의, 중립 또는 모순하는 비율로 할루시네이션 및 충실도 점수를 정의한다.
문장 수준 함의(sentence-level entailment) 모델을 사용하는 데 있어 잠재적인 한계는 결과의 어떤 부분이 잘못되었는지를 정확하게 찾아내고 위치시키는 데 능력이 없다는 것이다.
* 자연어 추론 문제란, 두 문장이 주어졌을 때, 하나의 문장이 다른 문장과 논리적으로 어떤 관계에 있는지를 분류하는 것이다. 유형으로는 모순 관계(contradiction), 함의 관계(entailment), 중립 관계(neutral)가 있다.
4) Faithfulness Classification Metrics:
NLI 기반 지표에 대한 개선책으로 task-specific 데이터 셋에 대한 구축이 고려되고 있다. Faithfulness 데이터 셋은 NLI 데이터 셋보다 할루시네이션 평가에 더 적합하다. 그 이유는 NLI 데이터 셋의 함의나 중립과 Faithfulness는 동일하지 않기 때문이다. 예를 들어, 'Putin is U.S. president(푸틴은 미국 대통령이다)'라는 가설은 'Putin is president(푸틴은 대통령이다)'라는 전제에 대해 중립적이거나 함의적 일 수 있다. 그러나 Faithfulnes 관점에서 가설은 'U.S.(미국)'이라는 정보를 포함하고 있어 할루시네이션으로 간주한다.
5) LM-based Metrics:
These metrics leverage two language models (LMs) to determine if each token is supported or not
3.3 Human Evaluation
자연어 생성(NLG) 태스크에서 할루시네이션에 대한 Automatic evaluation은 어려움과(challenging) 불완전성(imperfect) 때문에 Human Evaluation이 여전히 일반적으로 많이 사용되는 평가 방식 중 하나이며 평가 방식에는 두 가지 주요 형태가 있다.
- Scoring: human annotator가 정해진 범위내에서 할루시네이션 수준을(level) 평가하는 것
- Comparison: human annotator가 출력 결과를 특정 기준이나(baseline) 정답에 대한 레퍼런스와 비교하는 것
4. Hallucination in Generative Question Answering
생성적 질문 응답(Generative Question Answering, GQA)은 제공된 문맥에서 질문에 대한 답변을 추출하는 것이 아니라 추상적인 답변을 생성하는 것을 목표로 하는 태스크이다.
일반적으로 GQA 시스템은 질문과 관련된 정보를 찾기 위해 외부의 정보를 검색하는 과정을 포함한다. 그런 다음 검색된 정보를 기반으로 답변을 생성한다. 대부분의 경우 단일 출처(문서)에 답변이 포함되어 있지 않고, 여러 검색된 문서가 답변 생성을 위해 고려된다. 이러한 문서들은 중복 또는 모순된 정보를 포함할 수 있으며 따라서 생성된 답변에서 할루시네이션 현상이 흔하게 발생한다.
4.1 Hallucination Definition in GQA
GQA 태스크에서 명확한 할루시네이션에 대한 표준적인 정의는 없다. 그러나 특정 연구에서는 의미적 이동(semantic shift)이라는 용어를 사용하는데 이는 생성 과정에서 답변이 정확한 것으로(원하는 결과)부터 얼마나 이탈하는지를 나타내며 이는 GQA에서 할루시네이션의 특정한 정의로 볼 수 있다.
'2.1 Categorization 섹션'에서 정의한 할루시네이션을 기준으로 아래와 같이 GQA에 대한 예를 분류할 수 있다.
intrinsic hallucination: '다우 존스 산업 평균 지수가 무엇인가?(dow jones industrial average please?)'에 대한 답변으로 '30개 주요 미국 주식 지수(index of 30 major U.S. stock indexes)'가 생성되었는데 이는 '미국 주식 거래소에 상장된 30개의 유명한 기업들(of 30 prominent companies listed on stock exchanges in the United States)'이라는 위키피디아의 답변과 배치된다.
extrinsic hallucination: 'definiton of sadduction'에 대한 답변으로 'The definition of a Sadducee is a person who acts in a deceitful or duplicitous manner. An example of a Sadduceee is a politician who acts deceitfully in order to gain political power'라는 답변을 생성하였는데 이에 대한 내용은 원본 문서에서 확인할 수 없으므로 이를 외부 할루시네이션으로 분류한다.
4.2 Hallucination-related Metrics in GQA
현재 QGA에서 할루시네이션을 평가하는 자동지표(Automatic metrics)는 없다. 대부분의 GQA 작업에서는 ROUGE 점수나 F1과 같은 평가 지표를 사용하여 답변의 품질을 측정하지만, 이 N-gram 중첩 기반(N-gram overlap-based) 지표는 사람의 판단과 상관관계가 약하기 때문에 할루시네이션을 평가하는 의미 있는 방법이 아니다. 관련하여 sematic overlap, Factual consistency, zero-shot short answer recall과 같은 방법이 연구 및 제시되었다.
4.3 Hallucination Mitigation in GQA
GQA 초기 작업 대부분은 신뢰할 수 있는 외부 소스를 조사하거나 여러 정보 소스를 통합하여 답변의 충실도를 향상시키려고 노력하였다. 그럼에도 불구하고 이러한 방법들은 고품질의 관련 자료를 쉽게 구할 수 없는 상황에서 활용하기 쉽지 않다.
최근 QA 작업에서 언어 모델의 진실성을 측정하기 위해 38개 카테고리에 걸쳐 817개의 질문으로 구성된 벤치마크가(TruthfulQA) 제안되었다. 이 연구는 GPT-3, GPT-Neo/J, GPT-2 및 T5 기반 모델의 성능을 조사하였다. 결과적으로, 단순히 모델을 확장하는 것보다 튜닝을 통해 진실성을 개선하는 것이 더 유망하다는 것을 알 수 있다. 왜냐하면 큰 모델은 웹 데이터에서 학습 분포를 더 잘 배우기 때문에 더 많은 모방 거짓말을 생성하려고 하기 때문이다.
4.4 Future direction in GQA
첫째, 할루시네이션 현상을 측정하기 위해 더 나은 자동 평가 지표(automatic evaluation metrics)가 필요하다. 구체적으로, 현재 관련 지표들은 할루시네이션 측정시 각각 독립적인 관점 및 방법으로 측정하고 있는데 통일된 관점의 평가지표가 필요하다. 둘째, 현재 사용되는 GQA 데이터 셋에는 없는 할루시네이션 특징이 포함된 데이터 셋이 필요하다. 마지막으로, 할루시네이션 현상을 완화하는 또 다른 가능한 방법은 모델의 성능을 향상시키는 것이다. 질의(query)에 따른 관련 정보를 검색하는 검색 모델이 더 나은 성능을 가지고 다중 출처 문서로부터 더 정확한 답변을 할 수 있는 생성 모델이 필요하다.
'GPT > 문헌분석' 카테고리의 다른 글
| Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (0) | 2023.11.19 |
|---|---|
| LLaMA: Open and Efficient Foundation Language Models (0) | 2023.03.14 |

