
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- cnn
- 케라스
- 챗지피티
- 자연어
- 머신러닝
- 설명가능성
- 인공지능 신뢰성
- Ai
- Bert
- 신뢰성
- ChatGPT
- DevOps
- GPT-3
- ML
- gpt2
- 딥러닝
- word2vec
- 챗GPT
- fairness
- GPT
- MLOps
- 인공지능
- XAI
- 트랜스포머
- 지피티
- nlp
- trustworthiness
- AI Fairness
- Transformer
- Tokenization
- Today
- Total
research notes
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 본문
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
forest62590 2023. 11. 19. 10:36

1. Chain-of-Thought(CoT) 개요
- 최신 연구 결과 모델 크기를 확장하는(Scaling up)하는 것만으로는 산술(Arithmetic), 상식(Commonsense), 기호 추론(Symbolic reasoning)과 같은 까다로운 작업에서 LLM이 높은 성능을 달성하는 것이 쉽지 않음이 입증
- 이를 위한 해결방안으로 최종 출력(final output) 도출 과정에 'Chain-of-thought (CoT) <input, chain-of-thought, output>'라는 일련의 중간 자연어 추론 단계(intermediate natural language reasoning steps)를 포함한 프롬프트 구성 방법을 제시하고 LLM의 성능 평가 수행(사람도 특정 태스크를 해결할 때 단계별로 해결해 나가면서 최종 답변에 도달하게 되는데 이와 유사한 방식으로 프롬프트를 구성하여 LLM에 전달)
- 그 결과 산술, 상식, 기호 추론 태스크에서 CoT 방식의 프롬프트가 기존의 프롬프트 방식(Standard Prompting)을 능가한 뛰어난 성능 보임을 실험적으로(empirical) 입증
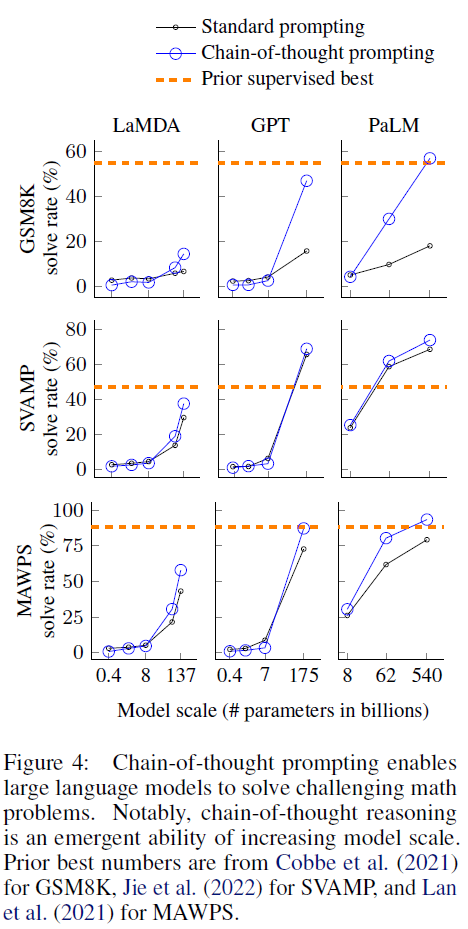
2. 실험환경 및 결과(For Arithmetic Reasoninig)
- (실험환경) 5개의 수학 벤치마크 데이터 셋(GSM8K, SVAMP, ASDiv, AQuA, MAWPS) 및 모델(GPT-3, LaMDA, PALM, UL2, Codex)을 활용
- (실험결과) 전반적으로 동일한 데이터 셋 및 모델에 대해 CoT 방법이 상대적으로 좋은 성과를 보였다. 다만, 100B 매개변수 미만의 모델에 대해서는 성능에 대한 이점이 크게 없는 것으로 발견됨

'GPT > 문헌분석' 카테고리의 다른 글
| Survey of Hallucination in Natural Language Generation (0) | 2023.03.26 |
|---|---|
| LLaMA: Open and Efficient Foundation Language Models (0) | 2023.03.14 |

