
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Transformer
- 머신러닝
- 인공지능 신뢰성
- ChatGPT
- nlp
- 인공지능
- fairness
- 설명가능성
- word2vec
- 챗지피티
- gpt2
- trustworthiness
- GPT
- Tokenization
- DevOps
- 신뢰성
- 트랜스포머
- GPT-3
- ML
- 케라스
- 지피티
- XAI
- MLOps
- Bert
- cnn
- 챗GPT
- Ai
- 자연어
- 딥러닝
- AI Fairness
- Today
- Total
research notes
SHAP (SHapley Additive exPlanations) 본문
1. SHAP 개요

SHAP(SHapley Additive exPlanations)는 머신러닝 모델의 출력을 설명하기 위한 협력 게임 이론에 기반한 접근법이며 SHAP value를 통해 feature importance를 파악할 수 있다.
** A Unified Approach to Interpreting Model Predictions 논문 참조 **
2. Additive Feature Attribution Method
선형회귀나 결정나무 같은 알고리즘은 그 자체로 출력 결과에 대한 설명이 가능하나, 앙상블 방식 혹은 딥러닝 등의 복잡한 모델의 경우는 블랙박스 특성상 설명하기가 매우 힘들다. 따라서, 복잡한 구조의 모델을 설명하기 위해서는 보다 단순한 모델을 활용하여 기존 모델을(original model) 근사해(approximation) 설명하는 방법이 고려될 수 있으며, 이때 근사시키는 모델을 explanation model(simpler explanation model) 이라고 한다.
정의: Binary(1/0) 변수의 선형결합으로 이루어진 Explanation 함수(g)

- : original prediction model to be explained
- f(x): a prediction based on a single input x
- : explanation model, local methods try to ensure g(z′) ≈ f(hx(z′)) whenever z′ ≈ x′.
- : mapping function,
- : simplified input,
- : attribution value
Definition1: Additive Feature Attribution Methods have an explanation model that is a linear function of binary variables
Explanation model은 로 각 feature에 대한 영향도를 나타내며, feature에 대한 의 영향도를 모두 더하면 기존 모델 f(x)의 출력과 근사한 값을 가지게 된다. 또한, 이하 기술된 방법들은 Additive Feature Attribution Method 방법 중의 하나이다.
ex) LIME, DeepLIFT, Layer-Wise Relevance Propagation, Shapley Value
3. Limitations of existing methods
기존의 feature attribution methods는 여러 한계점이 존재하였다. 예를 들어 LIME의 경우에는 같은 이미지를(being explained instance) 설명하더라도 랜덤 샘플링시 매번 슈퍼픽셀이 다르게 나오게 되어 output이 매번 달라 질 수 있기 때문에(Non-deterministic) 결과에 대한 일관성이 없다.

4. Simple properties uniquely determine Additive Feature Attribution

Additive Feature Attribution Method는 복잡한 인공지능 모델을 explanation model로 근사해 설명하는 방법을 말하며 explanation model의 형태는 Binary(1/0) 변수의 선형결합으로 이루어진 Explanation 함수(g)이다.
아래 3개의 프로퍼티 (Local Accuracy, Missingness, Consistency) 성질 및 Definiton 1을 만족하는 Explanation model g를 도출할 수 있는 유일한 방법은 g의 계수가(attributes) Shapley values 값을 가지는 것이다(Theorem1). 즉, Explanation model g의 계수(attributes)가 Shapely values가 아니라면 Propert1, 3을 만족시키지 못한다.




5. Shapley Values
- Shapley value introduction
(** Shapley value introduction 내용은 내용은 고려대 오혜령님 DMQA Lab seminar 참고자료 기반으로 작성 (이미지 및 내용) [Ref. 12]**)
◇ Shapley value는 게임이론(Game theory)을 바탕으로, 게임에서 각 플레이어의 기여도에 따라 상금을 공정하게 할당하기 위한 방법이며, 2012년에 노벨 경제학상을 수상한 Lloyd Shapley의 이름을 따서 명명되었다.

◇ Shapley Values는 플레이어의 Marginal contributions를 계산하여 가중 평균한 값
* Marginal contributions → 플레이어 전체 집합에 대해 가능한 모든 부분 집합마다 특정 플레이어 존재 여부에 따른 상금 변화량



- Shapley values equation

ϕi : i 데이터에 대한 Shapley Value
F : 전체 집합
S : 전체 집합에서, i 번째 데이터가 빠진 나머지의 모든 부분 집합
fS∪i(xS∪i) : i 번째 데이터를 포함한 (=전체) 기여도
fS(xS) : i 번째 데이터가 빠진, 나머지 부분 집합의 기여도
* 기존 shapely value 계산에서는 fS∪{i}와 fS가 각각 현재 사용되는 feature의 개수에 따라 다르게 학습된 후 사용된다(To compute this effect, a model fS∪{i} is trained with that feature present, and another model fS is trained with the feature withheld). 만약 데이터가 3개의 feature를 가지고 있다면 8번(2^3) 학습이 수행되기 때문에 상당히 많은 계산을 요하게 된다. 이 문제를 해결하기 위해서 missing value 개념과 fx(z')=f(hx(z′))=E[f(z)|zs)]를 사용하였다. fx(z')=f(hx(z′))라고 하면 사용되는 feature 차원이 같아지기 때문에 다른 개수의 feature 때문에 다시 학습을 수행할 필요가 없다.
- Shapley values in detail
모델의 예측 결과에 대해 각 feature들이 어떻게 영향을 미치는지 알아본다고 할 때 선형모델에서는 상대적으로 쉽게 그 영향력을 계산할 수 있다.

x는 기여도 계산에 활용되는 인스턴스이며 xj는(j=1, 2, ..., p) 각 feature에 대한 값이다. βj는 각 feature에 해당하는 가중치(weight)이다. 이때, 예측 결과 fhat(x)에 대한 j-th feature의 contribution ϕj 는 아래 공식과 같다.

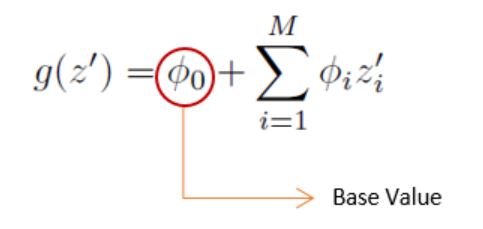
또한, 아래와 같은 공식이 도출 되는데, ②는 Explanation model에서 ϕ0 및 E[f(z)] (expected value, base value)와 같으며 ③ = ① + ②과 같은 식을 도출할 수 있는데, fhat(x)의 expectation value와 도출한 모든 Shapley values를 더한 값은 fhat(x)의 결과와 같아진다는 것이며, 향후 기술하는 "6. SHAP Values"에서 중요하게 활용되는 공식이다.

※ Expected value (base value, starting point, ϕ0)

def __dynamic_expected_value(self, y):
""" This computes the expected value conditioned on the given label value """
return self.model.predict(self.data, np.ones(self.data.shape[0]) * y).mean(0)Exptected value(base value)는 설명하려는 데이터의 결과에 대한 기댓값을 나타내며 이 값은 linear regression model에서 편향(intercept)와 같다고 보면 된다. 구하는 방법은 training data를 사용하여 학습 완료된 original model f(x)에 다시 설명하려는 데이터의 전체 데이터 셋을 사용해서 각 결과인 값(regression) 또는 확률(classification)을 학습데이터 row의 수만큼 평균을 내어 expected_value를 구한다.
Expected value는 SHAP force plot 등에서 reference point(staring point)가 되며, 이 값을 기준으로 특정 feature에 대한 SHAP value가 초과 또는 감소하였는지를 파악하여 어떠한 feature가 영향을 많이 미치는지 확인할 수 있다. 즉, SHAP values는 예측에 대한 각 feature들의 영향이나 방향을 수량화 한다.
6. SHAP Values

- Shapely values ≠ SHAP values
- Feature importance를 측정하기 위한 방법으로 SHAP values를 사용하며, 이 값은 원래 모델에(original model) conditional expectation function을 적용한 SHAP values이다. 또한, 아래 조건하에서 Equation8의 솔루션이 된다.

즉, Equation8에서 𝑓𝑥(𝑧)−𝑓𝑥(𝑧∖𝑖)=𝐸[𝑓(𝑧)|𝑧]−𝐸[𝑓(𝑧)|𝑧∖𝑖].
z': simplified input
S: the set of non-zero indexes in z'
hx(z') = zs, zs has missing values for features not in the set S

z'를 다시 복원하였을 때 z'에 missing values(weight, color)가 있는 경우 해당 값들을 랜덤하게 할당하게 된다. 또한, 대부분의 모델은 입력 값이 일정하지 않은 임의의 패턴을 다루지 못하기 때문에 f(zs)를 E(f(z)|zs)로 근사하여 근사치를 구한다.
7. Kernel SHAP
Equation2의 LIME 공식은 Equation8의 Shapley values 도출 공식과는 매우 다르게 보인다. 그러나 LIME은 additive feature attribution method이기 때문에, ϕi의 값들이 Shapley values가 된다면 property 1~3을 만족하는 Equation2의 Explain model을 구할 수 있는 유일한 솔루션임을 알 수 있다. 이러한 가정을 만족시키기 위해서는 Equation2의 L, Ω, πx'에 대한 정의가 필요하며 Theorem 2에서 이를 만족하는 Shapley kernel을 제시하였다.

※ KernelExplainer 코드 해석
np.random.seed(rand)
X_train_summary = shap.kmeans(X_train, 10)
shap_svm_explainer = shap.KernelExplainer(fitted_svm_mdl.predict_proba, X_train_summary)
shap_svm_values_test = shap_svm_explainer.shap_values(X_test[:100],nsamples=200, l1_reg="num_features(20)")#1.
X_test는 [734, 44]의 데이터 구성을 가지는 것으로 가정

#2
SHAP는 X_test의 모든 데이터의 각 feature들에 대해서 SHAP values를 도출한다.
#3
X를 설명하려는 데이터라고 할 때(being explained) X'는 simplified input이 되며 구성의 예는 다음과 같다.
X' = [1 1 1 1 1 ... 1 1 1] (44, )
≈z' = [1 1 0 1 0 ... 1 0 1] (44, )
#4
KernerExplainer의 nsamples는 기존 lime 알고리즘에서 사용되던 perturbed data들이라고 생각하면 된다. 즉, TreeExplainer에는 존재하지 않는다. 예를들어 nsamples가 200이면 X'를 기준으로 purturbed된 데이터 200개를 도출한다(z'가 200개). 참고로 nsamples는 default 개수가 2 * z' dimention (ex. 44 features) + 2048로 정해져있다.
#5
- KernerExplainer는 내부적으로 lime 알고리즘을 사용하여 수행된다.
- KernelExplainer에서 사용된 두번째 파라미터 (X_train_summary)은 background data라고 불린다. 주 역할은 SHAP의 missing value 계산시에 replacement 값으로 사용된다. background data가 100개가 넘어갈시 연산속도가 느려질 수 있다고 SHAP 사용시 warning을 주고 있다.
- z'를 original value로 변경할 때 기존의 lime은 missing value의 값을 0으로 처리했다. 그러나 SHAP에서는 missing value를 background data를 활용해서 처리해준다.
- background data를 10개 만들었다고 하면 missing value 위치에 background data의 값을 넣고 원복. 그 다음 f(hx(z′))를 도출한다. 즉, missing value는 background data의 값으로 대체하고, 예를 들어 missing value 위치에 background data의 값이 7, 9 였다면, 6, 25, 7, 0625, ..., 9] 로 변환하고 fitted_svm_mdl.predict_proba를 이용하여 예측값을 획득.
- ex) X= [6, 25, 625, 0625, ..., 62590] shape: (44, ) → z' = [1, 1, 0, 1, 1, 1, ..., 0] shape: (44, ) => hx(z') → z로 변형 했을 때 X 기준으로 변형을 하면 z=[6, 25, missing, 0625, ..., missing] (z'의 0값은 missing value)
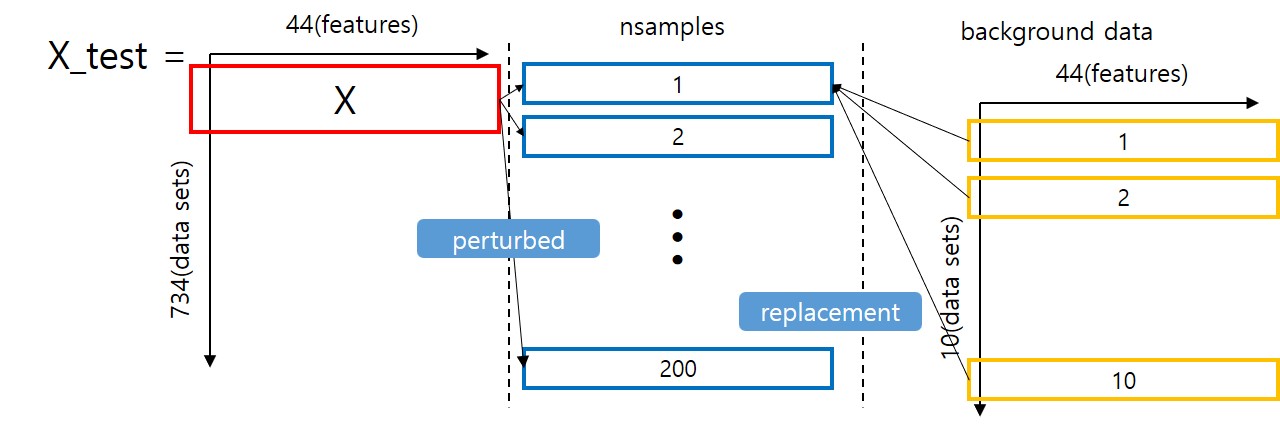
- 하나의 nsample(z')에 background data 개수만큼의 prediction 수행 후 기댓값을 구하면(E[f(z)|zs]) nsample에 대한 target value가 된다. 해당 절차를 모든 nsample만큼 수행하게 되면 (nsamples, target value(E[f(z)|zs]))를 200개 획득하게 되고 l1_reg를 통한 학습을 수행하게 되면 최종적으로 X_test data의 X(being explained)에 대한 SHAP values를 얻을 수 있다.
- 전체 데이터 셋의 1row마다 SAHP value를 구할 때 KernelExplainer는 총 nsamples * background data (ex. 200 * 10)번의 연산을 수행한다.
- 만약 background data나 nsamples가 늘어나면 그만큼 연산속도가 엄청 느려진다.

- 이 때 도출된 g의 ϕ1, ϕ2 등은 결국 SHAP value가 된다.
- 위 예에서 class=0, class=1 일 때의 SHAP value를 구하게 되어 최종적으로 [2, 734, 44]의 결과가 도출된다. 이 때 l1_regularization을 수행하였기 때문에 일부 ϕi의 SHAP value는 0으로 관찰된다.
- E(x) 또는 expected_value는 X_test data 734개에 대한 f(x)예측 값을 구하고 734로 나누어 도출할 수 있으며 동시에 starting point가 된다.
8. SHAP Explainers
- TreeExplainer, DeepExplainer, GradientExplinter, LinerExplainer는 모델의 구조 또는 파라미터를 활용하기 때문에 model-specific하다.
- DeepExplainer및 GradientExplainer는 딥러닝 프레임워크인 TensorFlow/Keras 및 PyTorch에서만 동작한다.

9. SHAP KernerExplainer 수행결과

References:
[1] https://github.com/PacktPublishing/Interpretable-Machine-Learning-with-Python
[3] A unified approach to interpreting model predictions, S Lundberg, https://arxiv.org/abs/1705.07874
[4] https://medium.com/analytics-vidhya/explain-ml-models-shap-library-5ce375c85d7d
[5] https://towardsdatascience.com/explain-your-model-with-the-shap-values-bc36aac4de3d
[6] https://www.topbots.com/explainable-ai-marketing-analytics/
[7] https://kicarussays.tistory.com/32?category=986894
[8] https://velog.io/@tobigs_xai/2주차-SHAP-SHapley-Additive-exPlanation
[9] https://www.youtube.com/results?search_query=skku+shap
[10] https://christophm.github.io/interpretable-ml-book/shapley.html
[11] https://bjlkeng.github.io/posts/model-explanability-with-shapley-additive-explanations-shap/
[12] 고려대 DMQA Lab seminar, https://www.youtube.com/watch?v=BQSkV95Dy4s
[13] https://edden-gerber.github.io/shapley-part-1/
[14] https://ai.plainenglish.io/understanding-shap-for-interpretable-machine-learning-35e8639d03db
[15] https://ko.wikipedia.org/wiki/%EA%B2%8C%EC%9E%84_%EC%9D%B4%EB%A1%A0
'인공지능 신뢰성 > eXplainable AI(XAI)' 카테고리의 다른 글
| Partial Dependency Plot (PDP plot) (0) | 2022.06.23 |
|---|---|
| Permutation Feature Importance(PFI) (0) | 2022.03.23 |
| LIME (Linear Interpretable Model-agnostic Explanation) (0) | 2022.02.26 |
| Image-specific Saliency (0) | 2022.02.22 |
| Class Activation Map (CAM) (0) | 2022.02.22 |



