
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- GPT
- trustworthiness
- 자연어
- Ai
- Tokenization
- 인공지능
- DevOps
- 설명가능성
- XAI
- MLOps
- 머신러닝
- 딥러닝
- 케라스
- ML
- word2vec
- 인공지능 신뢰성
- fairness
- cnn
- 지피티
- 트랜스포머
- GPT-3
- gpt2
- ChatGPT
- 챗GPT
- 신뢰성
- Bert
- AI Fairness
- Transformer
- 챗지피티
- nlp
- Today
- Total
research notes
LIME (Linear Interpretable Model-agnostic Explanation) 본문
LIME (Linear Interpretable Model-agnostic Explanation)
forest62590 2022. 2. 26. 17:121. LIME 개요
LIME은 개별 예측을 설명하는 데 활용할 수 있는 시각화 기술 중 하나이며, Model-agnostic 하므로 특정 분류 또는 회귀 모델에 적용할 수 있다.

복잡한 모형을 해석이 가능한 심플한 모형(Surrogate Model*)으로 locally approximation을 수행하여 설명을 시도한다. 이름에서 알 수 있듯 전체 모델이 아닌 개별 prediction의 근방에서만 해석을 시도한다는 점과 어떠한 모델 (딥러닝, 랜덤 포레스트, SVM 등) 및 데이터 형식도(이미지, 텍스트, 수치형) 적용이 가능하다는 특징이 있다.
- 오늘날 신경망과 같이 복잡성이 높은 머신러닝 모델을 사용하는 일반적인 상황에서, 예측 결과에 대하여 전역적으로 완벽한 설명을 제시하는 것은 현실적으로 매우 어려운 일이다. 비록 머신러닝 모델의 전체 예측 결과에 대하여 완벽한 설명을 한 번에 제시하는 것은 불가능하더라도, 적어도 사용자가 관심을 가지는 몇 개의 예측 결과에 한하여 즉각적으로 설명을 제시해 줄 수 있다.

즉, LIME은 딥러닝과 같은 복잡한 모델(complex-models)이 로컬 레벨에서 어떻게 행동하는지 묘사하기 위하여 설명하려는 관측지(the instance being explained) 주의에서 간단한 모델을(simple-models) 활용하여 맞추려고한다(fit). 그리고 해당 간단한 모델을 활용하여 더 복잡한 모델의 예측 결과를 국소적으로(locally) 설명할 수 있게 한다. 또한, LIME은 표 형식 데이터, 텍스트 데이터 및 이미지 데이터 세 가지 입력 형식을 지원한다.
* Surrogate Model: 원래 모델 자체로 해석하기 어려울 때 외부에 구조가 간단한 대리 (Surrogate) 모델을 사용하여 해석
* LIME을 활용하여 왜 이런 결과가 나왔는지에 대해 분석할 수 있을 뿐만 아니라 모델 개발 중 디버깅 또는 모델 간 비교에서 활용 할 수 있다.
2. LIME 수행 순서 (for tabular data)
① Create the perturbed data
② Predict the output on the perturbed data by using the black-box model. The results from the previous task will be used as the target value for the surrogate model
③ Create discretized features
④ Find the euclidean distance of perturbed data to the original observation
⑤ Convert distance to the similarity score
⑥ Train the surrogate model by using the perturbed data and target values
⑦ Select the top-n features from the surrogate model weights
3. Interpretable Data Representations
블랙박스 모델을 해석하기 위해서는 우선 활용되는 데이터 형태가 사람이 해석할 수 있는 형태로 표현되어야 한다. 즉, 실제로 모델 학습에 활용 되는 데이터의 형태와는 별개로 인간이 해석할 수 있는 형태로 나타내는 것이 요구되며 이를 Interpretable Data Representation이라고 한다.
- 텍스트 데이터: 텍스트 모델을 학습할 때는 word embeddings과 같은 복잡한 형태의 feature를 사용하지만, surrogate model 학습시에는 단어의 존재(1) 또는 부재(0)와 같이 단어의 존재 유무를 나타내는 이진벡터를 활용하여 surrogate model 학습에 활용할 수 있다.
- 이미지 데이터: 이미지 모델을 학습할 때는 RGB 값을 가지고 있는 이미지가 학습에 사용될 수 있으며, surrogate model 학습시에는 super-pixel로 이미지 세그먼트를 수행하고 해당 데이터를 학습에 사용할 수 있다.
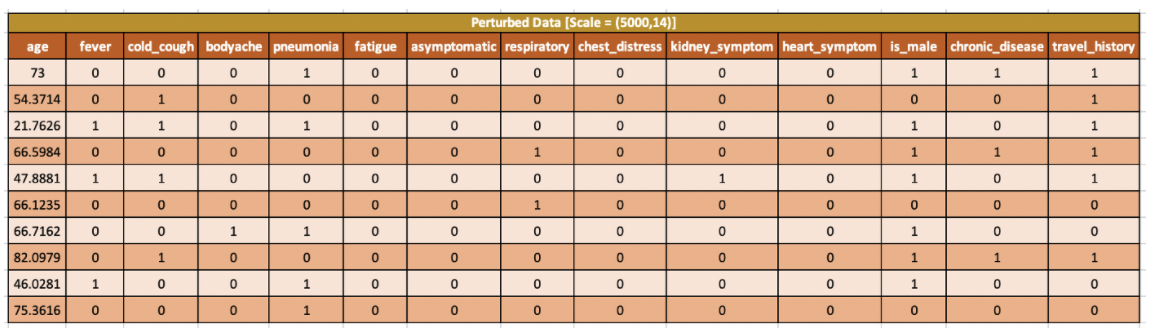
4. Perturbed data set for tabular data
Tabular data가 실제 LIME에서 어떠한 interpretable representation으로 활용되는지 궁금하여 찾아보다가 괜찮은 자료가 나와서 작성 시작... 해당 내용은 tabular data를 기반으로 LIME을 수행할 때 tabular data가 어떠한 형태로 구성되고 활용 되는지에 대해 작성 (Ref: [1] Unboxing the black box using LIME).
- 아래 tabular data는 instance being explained. 즉, 해당 데이터의 결과에 대한 해석을 필요로 한다.

- 관측치 설명을 위해 약간의 값을 수정하여 perturbed한 데이터를 n번 생성한다. 예를 들어 해당 데이터는 로컬 선형 모델 구축을 위해 사용되는 관측지 주변에 생성된 가짜 데이터이다. perturbed 샘플 데이터 생성 수 n은 하이퍼파라미터에 의해 결정되며 초기값은 5000이다.
- 범주형 변수의 경우, 훈련 데이터 세트에서 가능한 범주 값과 발생 빈도를(frequency) 기반으로 무작위 값을 선택한다. perturbed 데이터는 범주형 변수(데이터)에 대해 0 또는 1의 값을 갖는다. 범주가 설명해야 할 관측치와 같으면 1 아니면 0이다.
- 연속형 변수의 경우 데이터는 학습데이터 기준으로 정규분포에서(평균0, 분산1) 데이터를 샘플링하고, 다시 해당 데이터에 분산을 곱하고 평균을 더해주는 방법으로 perturbed 데이터 셋을 구한다.
- 위 두 과정은 feature 각각별 수행이 된다.
- 향후 quartile, entropy과 같은 이산화(discretization)과정을 수행한다.
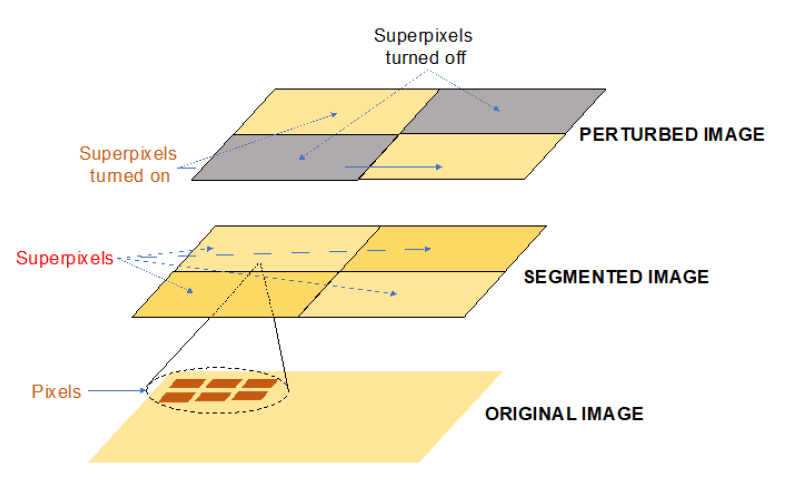
5. Perturbed data set for image data in LIME
LIME에서는 이미지를 여러 "세그먼트" 또는 "슈퍼 픽셀"(LIME super-pixel)로 분할하고 임의의 슈퍼 픽셀을 켜고 끄는 방식으로 perturbed 이미지를 생성한다. 이미지를 슈퍼픽셀로 분할하는 이유는 상관관계가 있는 픽셀을 함께 그룹화하여 최종 예측에 미치는 영향을 살펴보려고 하기 때문이다.
6. Perturbed data set for text data in LIME
텍스트 데이터는 테이블, 이미지 데이터와 다른 방식으로 변형이 이루어진다. 새로운 텍스트는 원래 텍스트에서 임의로 단어를 제거하여 만들어진다. 데이터셋은 각 단어에 대해 이진 변수로 표현되는데, 단어가 변수에 포함되면 1, 제거되면 0의 값을 지닌다.
예를 들어, 유튜브 댓글에 대해 스팸인지, 아닌지를 분류한다고 할 때 각 댓글은 하나의 문서(=행)가 되고, 각 컬럼은 특정 단어의 등장 여부를 나타낸다.
먼저 각 댓글과 그에 따른 클래스(스팸:1, 정상: 0)는 아래 형태와 같다.
| CONTENT | CLASS | |
| 267 | PSY is a good guy | 0 |
| 173 | For Christmas Song visit my channel! ;) | 1 |
173번의 문장에 대한 변형을 데이터프레임화 시키면 아래 형태와 같다. value값 1은 각 문서(=행)에 해당 단어(=컬럼)가 포함됨을, 0은 포함되지 않음을 의미. 3번 문서의 경우 "Christmas Song visit my ;)" 가 된다.
| For | Christmas | Song | visit | my | channel! | ;) | prob | |
| 2 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0.09 |
| 3 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0.09 |
| 4 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0.99 |
| 5 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0.09 |
| 6 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0.99 |
7. Select the top n features for the model
예측에 영향을 미친 상위 n가지 특징에 대해서만 알고자 할 수 있으며, LIME은 highest weights, forward selection, lasso path와 같은 feature selection 방법을 지원한다.
- Highest Weights — runs ridge regression on the scaled data with all features and picks top n features with highest weights
- Forward Selection — iteratively adds features to the model and identifies the features that give the best score on the ridge model.
- Lasso Path — chooses features based on lasso regularization path
- none — considers all the features
- auto — if num_features (m) <= 6, forward selection else highest weights
8. LIME example
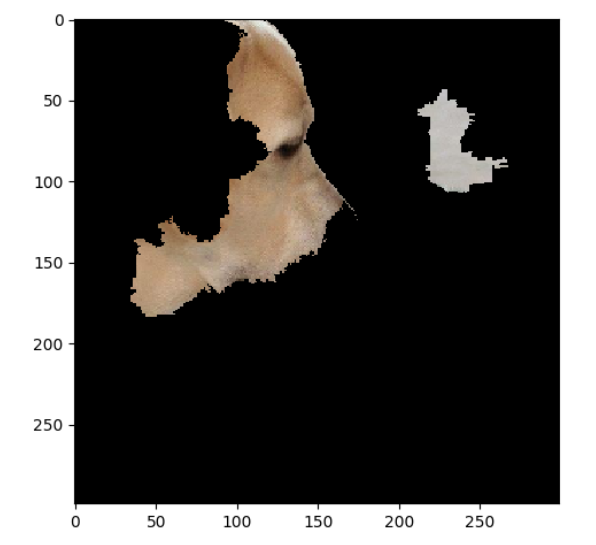
① 먼저 이미지를 super-pixel이라고 불리는 해석 가능한 요소로 쪼개는 전처리 과정 수행

② 그리고 나서 변수에 약간의 변화(perturbation)를 준다. 이미지의 경우에는 super-pixel 몇개를 찝어서 회색으로 가리고 모델을 통해 예측값을 구한다. 만약 예측값이 많이 변하면 가렸던 부분이 중요했다는 것을 알 수 있으며, 반대로 예측값이 많이 달라지지 않았으면 가렸던 부분이 별로 중요하지 않다라는 것을 알 수 있다.
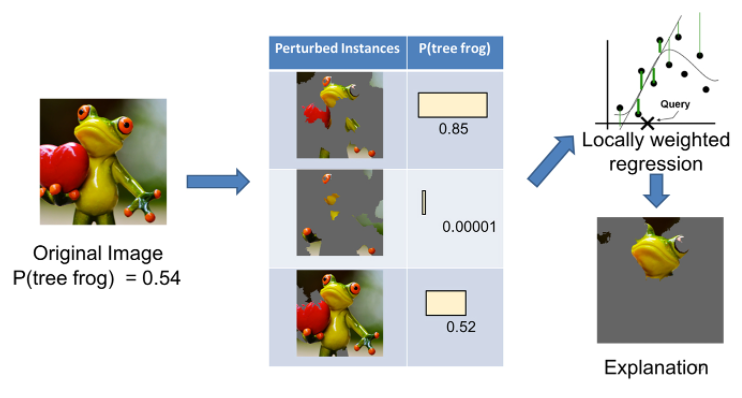
③ 위 예시에서 원본 사진은 0.54 확률로 개구리로 예측이된다.
- 이 사진을 첫번째 변형(perturbed instance)처럼 가렸더니 개구리일 확률이 0.85로 높아졌다. 사진에서 남은 부분이 개구리라고 예측하는 데 중요한 요소라는 것을 알 수 있다.
- 두번째 변형처럼 가렸더니 개구리일 확률이 0.00001로 매우 낮아졌다. 그러면 방금 가린 부분이 개구리라고 판단하는 데 중요한 요소였다는 것을 알 수 있음.
- 세번째 변형처럼 가리면 개구리일 확률이 별로 변하지 않는다. 이때 가린 부분은 개구리라고 판단하는 데 별로 중요하지 않았다는 것을 알 수 있다.
- 이렇게 여러번의 과정을 거친 뒤 결국 어떤 super-pixel이 개구리라고 판단하는 데 가장 중요했는지 찾는 것이 LIME의 핵심.
④ 내용보충
LIME에서는 black-box model과 surrogate model은 서로 다른 데이터 공간에서 작동한다. 예를 들어 ImageNet 데이터에 대해 훈련된 VGG16 신경망을 고려해 보자. 해당 모델은 244 × 244 픽셀 크기의 이미지를 입력으로 사용하고 이미지가 1000개의 카테고리 중 어느 클래스에 속하는지 예측한다. 원래 공간 X는 차원이 3 × 244 × 244(단일 픽셀 × 244 × 244 픽셀에 대한 3개의 단색 채널(빨강, 녹색, 파랑))을 사용한다. 즉, 입력 공간은 178,608차원을 가진다. 이러한 고차원 공간에서 예측을 설명하는 것은 어렵기 때문에, 단일 관심 인스턴스의(to be explained) 관점에서 공간은 켜거나 끌 수 있는(turn on/off) 이진 기능으로 처리되는 슈퍼픽셀로 변환될 수 있다. 아래 그림은 surrogate model을 학습하기 위해 임의로 생성된 100개의 슈퍼픽셀의 예를 보여준다. 따라서 이 경우 블랙박스 모델 f( )는 공간 X = R^178608에서 작동하는 반면 유리 상자 모델 g( )는 공간 X* = { 0 , 1 }^100 에 적용된다.

9. 이미지 판별에 대한 LIME 활용
① Generate random perturbations for input image
이미지의 경우 LIME은 이미지의 super-pixel 일부를 켜고 끄는 방식으로 이미지 섭동 (Perturbations)을 생성한다.
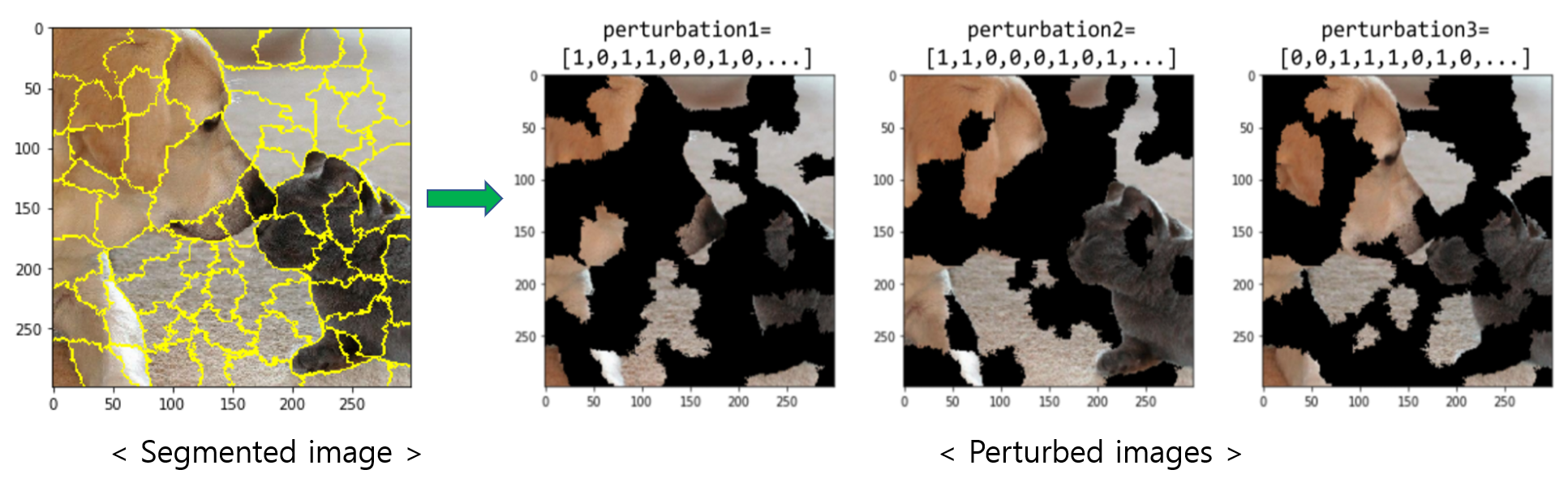
② Predict the class of each of the perturbed images
섭동 된 이미지를 사용하여 예측 결과를 얻는다. Inception v3 모델을 사용하는 경우 1000개의 클래스가 예측되며, 나중에 Surrogate Model을 학습하는 할 때 래브라도 클래스만 사용한다. 여기서 얻어진 래브라도 확률을 예측값으로 (섭동이미지, 래브라도 예측값) Surrogate Model을 학습시킬 데이터 셋을 새로 구축한다.
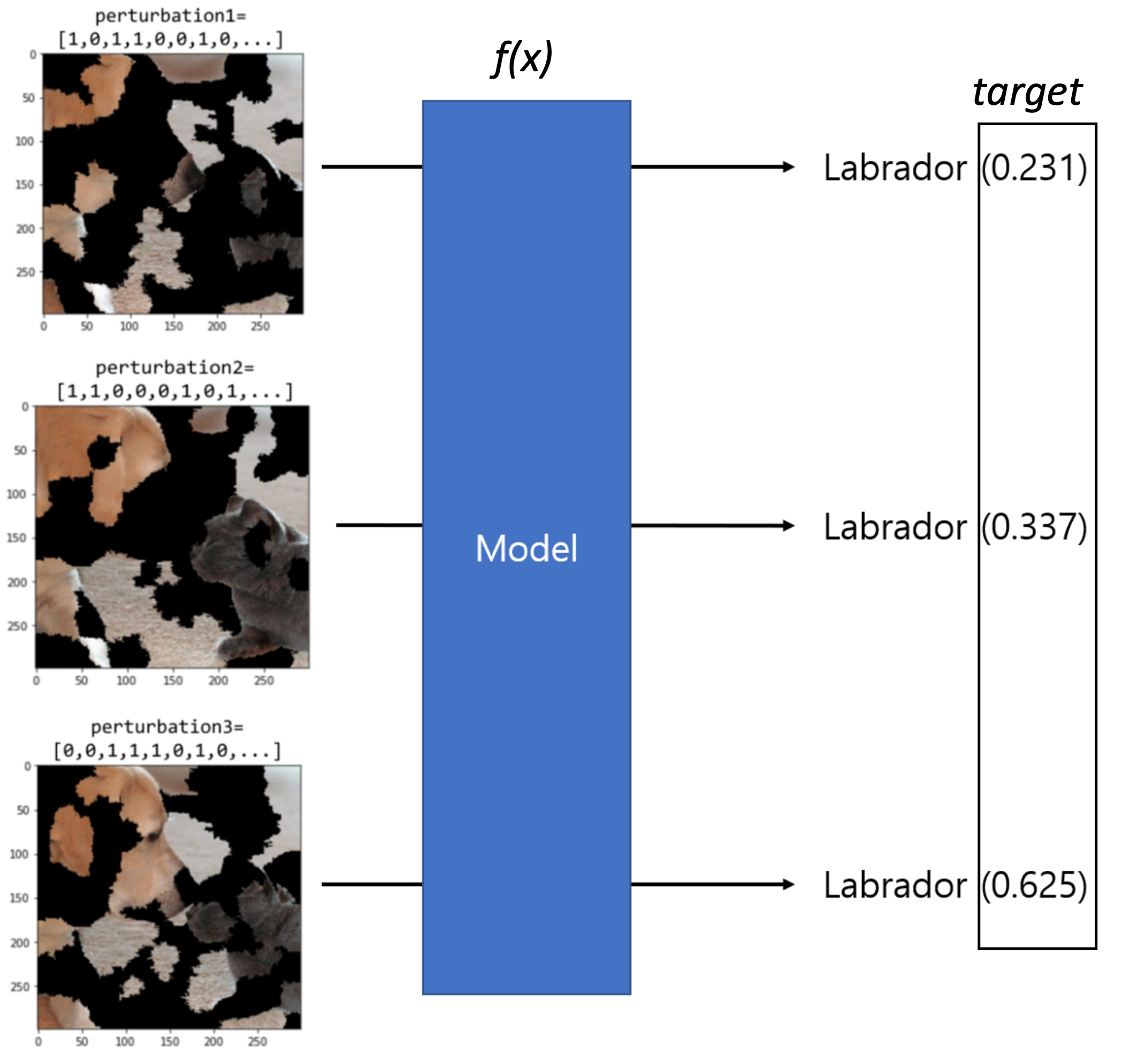
③ Compute weight (importance) for the perturbations
거리 값을 사용하여 각 섭동이 원본 이미지로부터 얼마나 떨어져 있는지 평가한다. 원본 이미지에서 가까이 있을수록 가중치를 크게 주고 멀리 있으면 작게 만들어 원본 이미지 주변 Local의 특성을 최대한 살린다
④ Fit a explainable liner model using the perturbations, predictions and wieght
이전 단계에서 얻은 정보를 사용하여 선형 모델을 학습시킨다. 학습 된 모델에서 각 계수 (coefficient)의 Rank를 부여하였을 때 가장 높은 값 순으로 래브라도 클래스의 예측에 가장 많은 영향을 미친 super-pixel이 된다.
⑤ Summary
- "래브라도 리트리버"의 예측과 더 강한 연관성을 가진 이미지 영역(슈퍼 픽셀)이 활성화 된다.
- 인공지능 모델이 주어진 이미지에 대한 래브라도 클래스를 어떤 근거로 예측하고 있음을 확인할 수 있다.
- 즉, LIME이 특정 예측을 반환하는 이유를 이해함으로써 기계 학습 모델에 대한 신뢰도를 높일 수 있음.
- lime explainer를 사용할 때 학습된 classifier를 전달해야 하는 이유는 해당 모델에다 perturebed된 데이터를 입력하여 결과를 얻고 그 결과가 local interpretatin 모델의 target값이 되기 때문이다.
10. 논문분석
① Interpretable Data Representation
Interpretable explanations need to use a representation that is understandable to humans, regardless of the actual features used by the model.
- (Text) Text classification is a binary vector indicating the presence or absence of a word, even though the classifier may use more complex (and incomprehensible) features such as word embeddings.
- (Image) an interpretable representation may be a binary vector indicating the “presence” or “absence” of a contiguous patch of similar pixels (a super-pixel), while the classifier may represent the image as a tensor with three color channels per pixel.
② Fidelity-Interoperability Trade-off
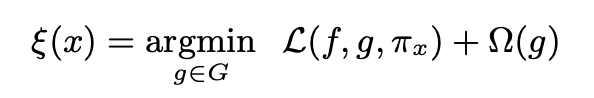
- Define an explanation as a model g ∈ G, where G is a class of potentially interpretable models
- linear models, decision trees, or falling rules lists
- As not every g ∈ G may be simple enough to be interpretable - thus let Ω(g) is a measure of complexity (as opposed to interpretability) of the explanation g ∈ G
- Decision trees → depth of the tree
- Linear models → the number of non-zero weights
- It uses the πx(z) as a proximity measure between an instance z to x, so as to define locality around x.
- In order to ensure both interpretability and local fidelity, we must minimize L(f, g, πx) while having Ω(g) be low enough to be interpretable by humans.
- Here we focus on sparse linear models as explanations.
③ Sampling for Local Exploration
They sample instances around x' by drawing nonzero elements of x' uniformly at random (where the number of such draws is also uniformly sampled). Given a perturbed sample z' ∈ {0, 1}^d' (which contains a fraction of the nonzero elements of x'), they recover the sample in the original representation z ∈ R^d and obtain f(z), which is used as a label for the explanation model. Given this dataset Z of perturbed samples with the associated labels, we optimize Eq. (1) to get an explanation ξ(x).
④ Sparse Linear Explanations
we let G be the class of linear models, such that g(z') = wg ·z'
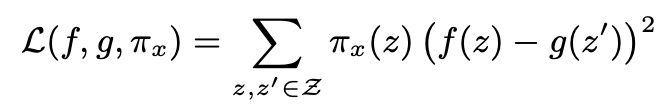

References:
[1] Unboxing the black box using LIME, Understanding the internals of LIME using COVID-19 data
https://towardsdatascience.com/unboxing-the-black-box-using-lime-5c9756366faf
[2] Why should I trust you?, Marco Tulio Ribeiro et al., https://arxiv.org/pdf/1602.04938.pdf
[3] How to Use LIME to Understand sklearn Models Predictions?, https://coderzcolumn.com/tutorials/machine-learning/how-to-use-lime-to-understand-sklearn-models-predictions
[4] https://yjjo.tistory.com/3
[5] http://shuuki4.github.io/deep%20learning/2016/08/24/Why-Should-I-Trust-You-논문-정리.html
[6] Explanatory Model Analysis, https://ema.drwhy.ai/LIME.html
[7] https://moondol-ai.tistory.com/396
[8] https://dreamgonfly.github.io/blog/lime/
[9] https://nhlmary3.tistory.com/entry/LIME-Locallly-Interpretable-Modelagnostic-Explanation
[10] https://realblack0.github.io/2020/04/27/explainable-ai.html
[11] https://sualab.github.io/introduction/2019/08/30/interpretable-machine-learning-overview-1.html
'인공지능 신뢰성 > eXplainable AI(XAI)' 카테고리의 다른 글
| Permutation Feature Importance(PFI) (0) | 2022.03.23 |
|---|---|
| SHAP (SHapley Additive exPlanations) (0) | 2022.03.16 |
| Image-specific Saliency (0) | 2022.02.22 |
| Class Activation Map (CAM) (0) | 2022.02.22 |
| Gradient-Class Activation Map(Grad-CAM) (0) | 2022.02.22 |



