
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- nlp
- cnn
- 지피티
- DevOps
- ChatGPT
- 챗GPT
- fairness
- MLOps
- 트랜스포머
- 인공지능
- 인공지능 신뢰성
- XAI
- 케라스
- 자연어
- ML
- GPT-3
- 챗지피티
- Transformer
- Tokenization
- Ai
- 신뢰성
- gpt2
- GPT
- 설명가능성
- Bert
- word2vec
- 머신러닝
- 딥러닝
- AI Fairness
- trustworthiness
- Today
- Total
research notes
트랜스포머(Transformer) 본문
다량의 말뭉치에 대한 의미와 문맥을 학습한 언어모델(language model)을 활용해 문서 분류, 개체명 인식 등 각종 태스크를 수행할 수 있으며, 요즘에는 트랜스포머(transformer) 기반의 언어모델이 각광받고 있으며 주로 자연어 처리에서 사용하는 딥러닝 아키텍처 중 하나이다. 현재 자연어 처리의 역사는 트랜스포머와 함께하고 있다고 해도 과언이 아니다. BERT, GPT 등 요즘 널리 쓰이는 모델 아키텍처가 모두 트랜스포머이다. 또한 자연어 처리 외에 비전, 음성 등 다양한 분야에 널리 활용되고 있다.
※ BERT, GPT 따위의 부류는 미리 학습된 언어 모델(pretrained language model)이라는 공통점이 있다.
※ 기존의 RNN 및 LSTM과 같은 네트워크는 장기 의존성 문제(long-term dependency)를 가진다.
- 장기의존성 문제: RNN이 은닉상태(hidden state)를 통해 과거의 정보를 저장할 때 문장의 길이가 길어지면 앞의 과거 정보가 마지막 시점까지 전달되지 못하는 현상을 말한다.
※ 최근들어 언어 모델이 주목받는 이유중 하나는 ‘다음 단어 맞히기’나 ‘빈칸 맞히기’ 등으로 학습 태스크를 구성하면 사람이 일일이 수작업해야 하는 레이블 없이도 많은 학습 데이터를 싼값에 만들어낼 수 있기 때문이며, 또 다른 이유는 트랜스퍼러닝으로 대량의 말뭉치로 프리트레인한 언어모델을 문서 분류, 개체명 인식 등 다운스트림 태스크에 적용해 적은 양의 데이터로도 성능을 큰폭으로 올릴 수 있기 때문이다.
1. 언어 모델(Language model)
언어 모델이란 단어 시퀸스에 확률을 부여하는 모델이다.
다시 말해 단어 시퀀스를 입력받아 해당 시퀀스가 얼마나 그럴듯한지에 대한 확률을 출력으로 하는 모델이다. 따라서 한국어 말뭉치로 학습한 언어 모델은 자연스러운 한국어 문장에 높은 확률값을 부여한다.
◇ 순방향 언어모델(forward language model)
잘 학습된 한국어 모델이 있다면 P(\(w_{1}\), \(w_{2}\), \(w_{3}\), ..., \(w_{n}\))은 높은 확률값을 나타낼 것이다. P(\(w_{1}\), \(w_{2}\), ..., \(w_{n}\))은 문장에서 i번째로 등장하는 단어를 \(w_{i}\)라고 할 때 n개 단어가 동시에 나타날 결합확률이며, 잘 학습된 한국어 모델이라면 P(무모, 운전)보다는 P(난폭, 운전)이 큰 확률 값을 지닐 것이다.
전체 단어 시퀀스가 나타날 확률(다음 수식 좌변)은 이전 단어들이 주어졌을 때 다음 단어가 등장할 확률의 연쇄(다음 수식 우변)와 같다고 할 수 있으며, 이 때문에 언어 모델을 이전 단어들이 주어졌을 때 다음 단어가 나타날 확률을 부여하는 모델이라고 정의하기도 한다.

임의의 단어 시퀀스가 해당 언어에서 얼마나 자연스러운지 이해하고 있는 언어 모델을 구축하려고 할 때, 언어 모델의 학습 방식을 이전 단어들(컨텍스트)이 주어졌을 때 다음 단어 맞추기로 정해도 목표를 달성할 수 있다.
회색 단어는 컨텍스트, 붉은색 단어는 맞혀야할 다음 단어를 의미하고 문장 앞부터 뒤로, 사람이 이해하는 순서대로 계산하는 모델을 순방향(forward) 언어모델이라고 한다. GPT 모델이 이런 방식으로 프리트레인을 수행한다.

◇ 마스크 언어 모델(masked language model)
한편 언어 모델은 P(W|context)와 같은 수식으로도 나타낼 수 있는데 그 의미는 컨텍스트(context; 주변 맥락 정보)가 전제된 상태에서 특정 단어(w)가 나타날 조건부 확률을 말한다. 이렇게 정의된 언어모델은 단어나 단어 시퀸스로 구성된 컨텍스트를 입력 받아 특정 단어가 나타날 확률을 출력한다.
학습 대상 문장에 빈칸을 만들어 놓고 해당 빈칸에 올 단어로 적절한 단어가 무엇일지 분류하는 과정으로 학습하며 BERT가 마스크 언어 모델로 프리트레인하는 대표적인 모델이다.
아래 그림의 첫줄에서 컨텍스트는 [MASK] 카페 갔었어 거기 사람 많더라이고 맞힐 대상 단어는 어제이다. 마스크 언어 모델은 맞힐 단어를 계산할 때 문장 전체의 맥락을 참고할 수 있다는 장점이 있어 언어 모델에 양방향(bidirectional) 성질이 있다고도 한다.
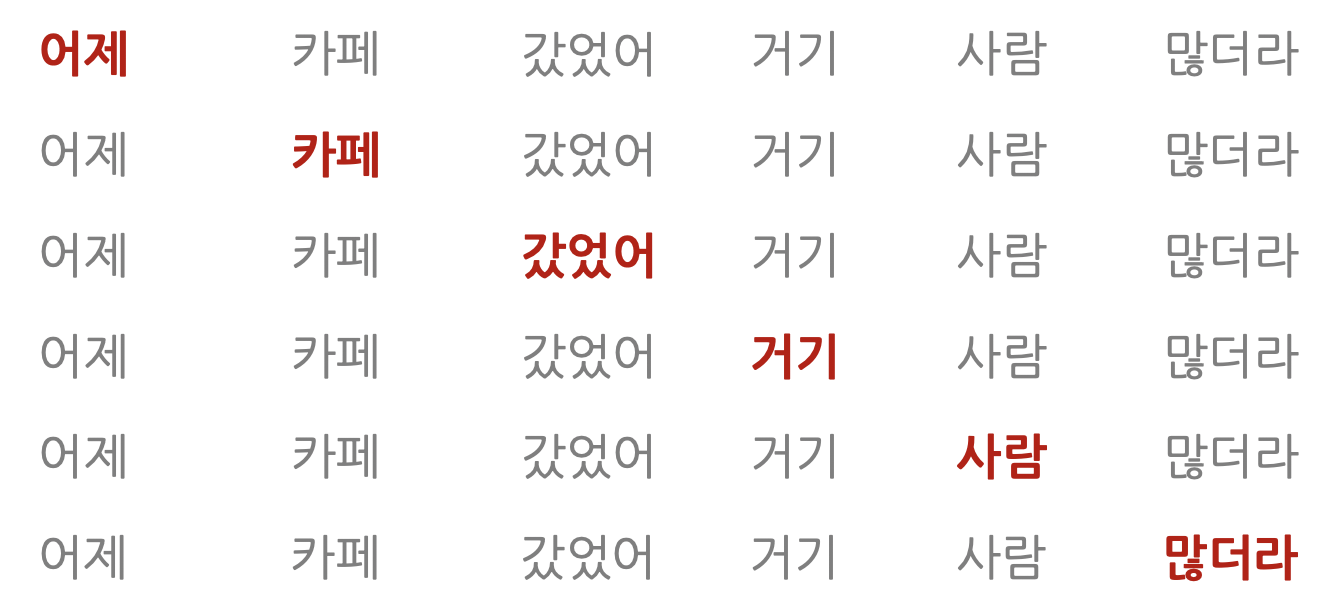
◇ 스킵-그램 모델(skip-gram model)
어떤 단어(context) 앞뒤에 특정 범위를(window) 정해 두고 이 범위 내에 어떤 단어들이 올지 분류하는 과정을 학습하는 모델이며 Word2Vec이 스킵-그램 모델 방식으로 학습한다.

2. 트랜스포머(Transformer)
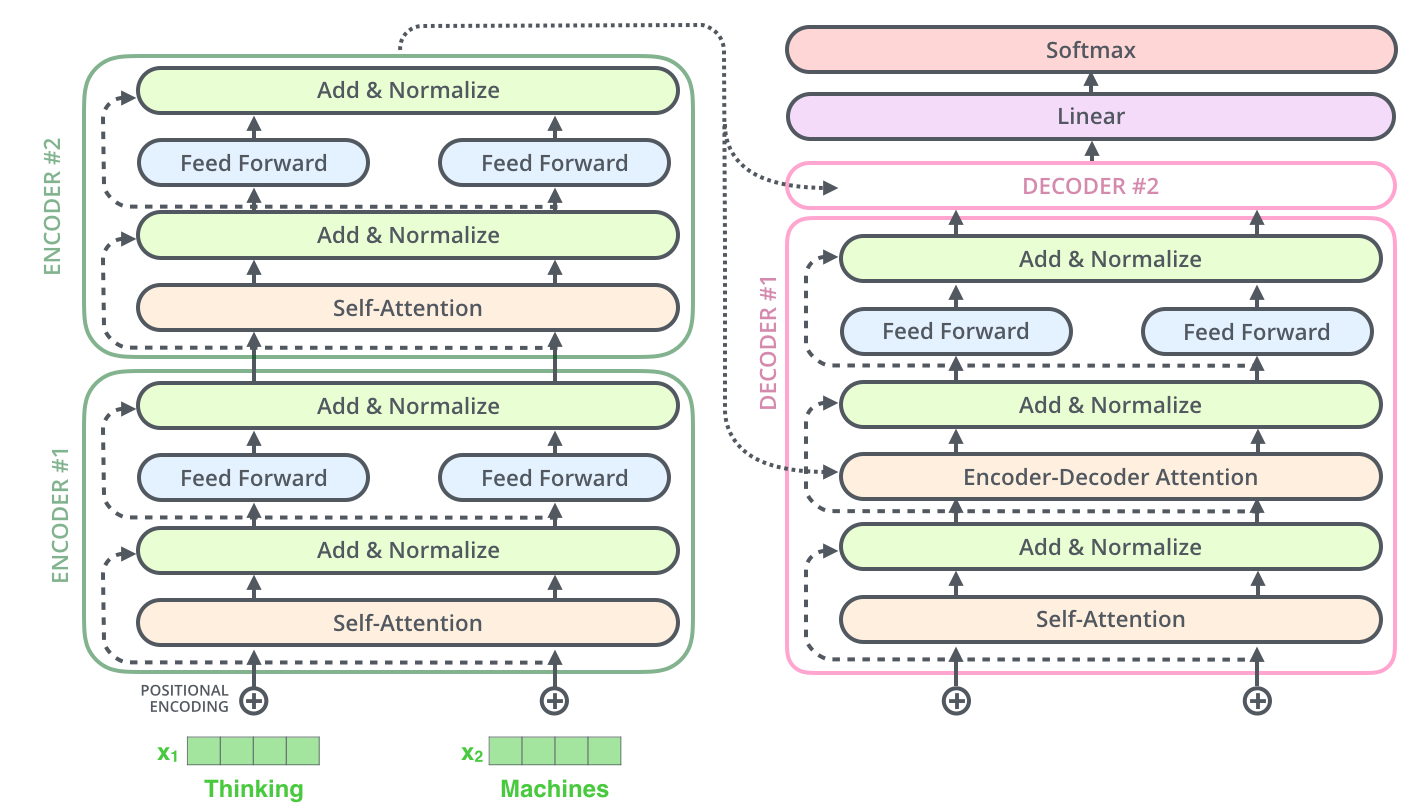
트랜스포머는 2017년 구글이 제안한 시퀸스-투-시퀸스 모델이며 자연어 처리에서 주로 활용되는 딥러닝 아키텍처이다. 트랜스포머 출현 이후로 RNN, LSTM 등은 트랜스포머로 대체 되었다. 시퀸스-투-시퀸스 과제를 수행하는 모델은 아래 그림처럼 대개 인코더(encoder)와 디코더(decoder) 2개 파트로 구성되며, N개의 인코더 혹은 디코더가 쌓인 형태다.
- 인코딩: 소스 스퀸스의 정보를 압축해 디코더로 소스정보 전달
- 디코더: 인코더로부터 소스정보를 전달받아 타겟 시퀸스 생성

최초 인코더에 대한 입력값으로 입력 문장을 넣게되고, 최종 인코더의 결괏값으로 입력 문장에 따르는 표현 결과를 얻는다. "Attention Is All You Need" 논문에서는 N=6으로 정의되어 있다(논문 상에서는 인코더 및 디코더가 각각 6개씩 쌓여있으나(stack) 특정한 이유가 존재하는 것은 아니다).


각각의 인코더는 구조가 모두 동일하며(가중치를 공유한다는 의미는 아님), 두 개의 하위 계층으로 나뉜다. (Self-Attention 및 Feed Forward Neural Network) 또한, 정확히 동일한 피드포워드 네트워크가 각 위치에 독립적으로 적용된다.
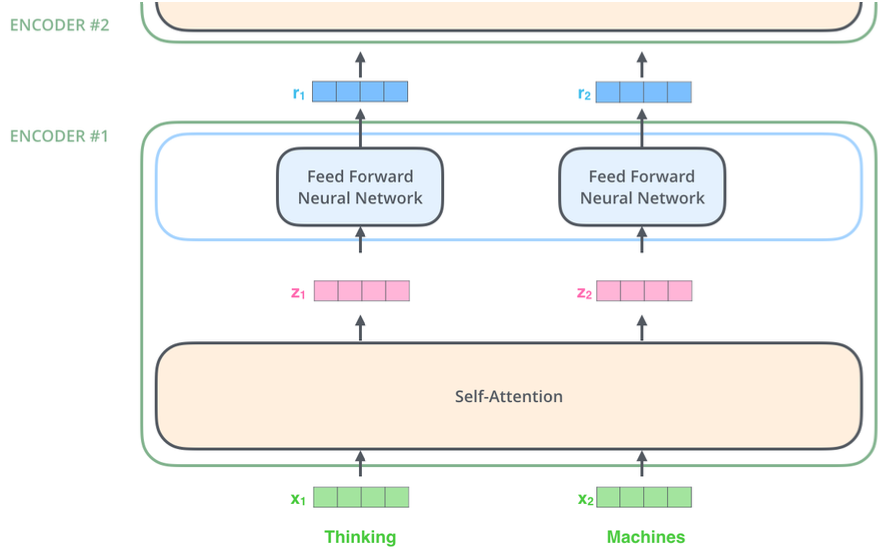
2.1. 트랜스포머 적용 기술
- 멀티헤드 어텐션(마스크 멀티 헤드 어텐션, masked multi-head attention)
- 피드포워드 뉴럴넷(feedforward neural network)
- 잔차연결(residual connection)
- 레이어 정규화(layer normalization)

2.2. 트랜스포머 학습
아래 그림처럼 I를 맞춰야 하는 차례라고 가정할 때 트랜스포머 학습방법은 다음과 같다.
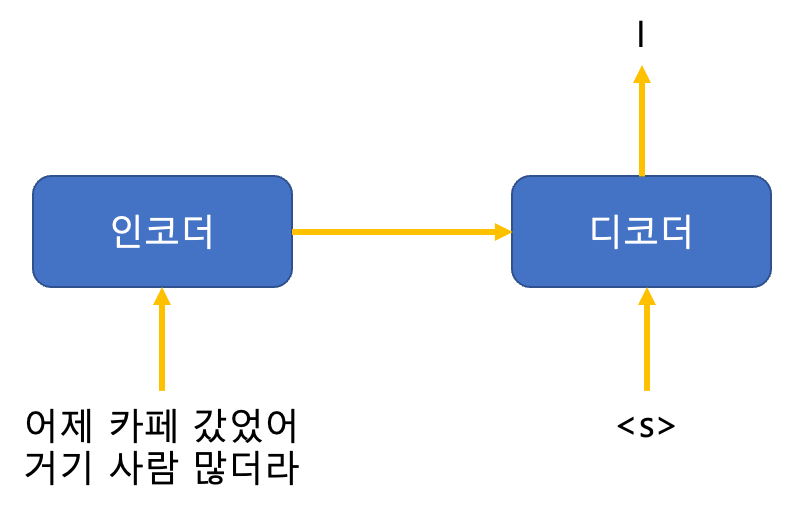
① 인코더 입력은 어제, 카페, 갔었어, 거기, 사람, 많더라 같이 소스 시퀀스 전체이고 디코더 입력은 <s>가 된다.
② <s>는 타깃 시퀀스의 시작을 뜻하는 스페셜 토큰이다.
③ 인코더는 소스 시퀀스를 압축해 디코더로 보내고, 디코더는 인코더에서 보내온 정보와 현재 디코더 입력을 모두 감안해 다음 토큰(I)을 맞힌다.
④ 트랜스포머의 최종 출력(디코더 최종 출력, Output Probabilities)은 타깃 언어의 어휘 수만큼의 차원으로 구성된 벡터(vector)이다. 예를 들어 타깃 언어의 어휘가 총 3만개라고 가정해 보면 디코더 출력은 3만 차원의 벡터이며, 이 벡터의 요솟값 3만개 각각은 0 이상 1 이하의 값을 가지며 모두 더하면 1이 된다.
⑤ 트랜스포머의 학습(train)은 인코더와 디코더 입력이 주어졌을 때 정답에 해당하는 단어의 확률 값을 높이는 방식으로 수행된다.

⑥ 학습 중의 디코더 입력과 학습을 마친 후 모델을 실제 기계 번역에 사용할 때(인퍼런스)의 디코더 입력이 다르다. 학습 과정에서는 디코더 입력에 맞혀야 할 단어(went) 이전의 정답 타깃 시퀸스(<s> I)를 넣어준다. 하지만 학습 종료 후 인퍼런스 때는 현재 디코더 입력에 직전 디코딩 결과를 사용한다. 예를 들어 모델 학습이 약간 잘못되어 인퍼런스 때 직전 디코더 출력이 I 대신 you라는 단어가 나왔다고 가정하면 이 때 다음 인코더 입력은 <s> you가 된다.
2.3. 셀프 어텐션(self-attention)
ex) A dog ate the food because it was hungry.
이 문장에서 'it'은 'dog'나 'food'를 의미할 수 있다. 하지만 문장을 자세히 살펴보면 'it'은 'food'가 아닌 'dog'를 의미한다는 것을 쉽게 알 수 있다. 위와 같은 문장이 주어질 경우 모델은 'it'이 'food'가 아닌 'dog'이라는 어떻게 알 수 있을까? 이 때 셀프 어텐션이 필요하다.


★ 셀프 어텐션을 수행하게 되면 특정 단어와 문장 내에 있는 모든 단어가 어떤 연관이 있는지를 이해할 수 있어 좀 더 좋은 표현을 학습시키는데 도움이 된다.
즉, 셀프어텐션이란 말 그대로 자신에게 수행하는 어텐션 기법.
아래 그림은 입력 시퀀스가 '어제, 카페, 갔었어, 거기, 사람, 많더라'일 때 '거기'라는 단어가 어떤 의미를 가지는지 계산하는 상황

잘 학습된 셀프 어텐션 모델이라면 '거기'에 대응하는 장소는 '카페'라는 사실을 알아챌 수 있을 뿐만 아니라 '거기'는 '갔었어'와도 연관이 있음을 확인할 수 있다. 트랜스포머 인코더 블록 내부에서는 이처럼 '거기'라는 단어를 인코딩할 때 '카페', '갔었어'라는 단어의 의미를 강조해서 반영한다.
셀프 어텐션 수행 대상은 입력 시퀀스 전체이다. '거기' 뿐만 아니라 실제로는 '어제-전체' 입력 시퀀스, '갔었어-전체' 입력 시퀀스, '사람-전체' 입력 시퀀스, '많더라-전체' 입력 시퀀스 모두 어텐션 계산을 한다.
이처럼 개별 단어와 전체 입력 시퀀스를 대상으로 어텐션 계산을 수행해 문맥 전체를 고려하기 때문에 지역적인 문맥만 보는 CNN 대비 강점이 있다. 아울러 모든 경우의 수를 고려(단어들 서로가 서로를 1대 1로 바라보게 함)하기 때문에 시퀀스 길이가 길어지더라도 정보를 잊거나 왜곡할 염려가 없어 RNN의 단점을 극복하였다.
어텐션과 셀프 어텐션의 주요 차이를 살펴보면 다음과 같다.
- 어텐션은 소스 시퀀스 전체 단어들(어제, 카페, …, 많더라)과 타깃 시퀀스 단어 하나(cafe) 사이를 연결하는 데 쓰인다. 반면 셀프 어텐션은 입력 시퀀스 전체 단어들 사이를 연결한다.
- 어텐션은 RNN 구조 위에서 동작하지만 셀프 어텐션은 RNN 없이 동작한다.
- 타깃 언어의 단어를 1개 생성할 때 어텐션은 1회 수행하지만 셀프 어텐션은 인코더, 디코더 블록의 개수만큼 반복 수행한다.
2.4. 셀프 어텐션 계산 예시
셀프 어텐션은 쿼리(query), 키(key), 벨류(value) 3가지 요소가 서로 영향을 주고 받는 구조이다.
셀프 어텐션은 쿼리 단어 각각을 대상으로 모든 키 단어와 얼마나 유기적인 관계를 맺는지를 그 합이 1인 확률 값으로 나타낸다. 그림을 보면 '카페'라는 쿼리 단어와 가장 관련이 높은 키 단어는 '거기(0.4)'라는 것을 확인할 수 있다.

셀프 어텐션 모듈은 이러한 결과에 벨류 벡터들을 가중합하는(weighted sum) 방식으로 계산을 마무리한다.
𝐙(카페) = 0.1×𝐕(어제)+0.1×𝐕(카페)+0.1×𝐕(갔었어)+0.4×𝐕(거기)+0.2×𝐕(사람)+0.1×𝐕(많더라)
나머지 모든 단어들에 대해서도 위와 같은 셀프 어텐션이 수행된다. 모든 시퀸스를 대상으로 셀프 어텐션 계산이 끝나면 그 결과를 다음 블록으로 전달한다. 트랜스포머 모델은 셀프 어텐션 블록(레이어) 수만큼 반복한다.
2.5. 트랜스포머 인코더 계산 수행 (셀프 어텐션)
입력 문장이 'I am good'이라고 가정할 때 각 단어의 임베딩:
- I(\(x_{1}\)) = [1.76, 2.22, ..., 6.66]
- am(\(x_{2}\)) = [7.77, 0.631, ..., 5.35]
- good(\(x_{3}\)) = [11.44, 10.10, ..., 3.33]
입력행렬(임베딩 행렬) X로 부터 쿼리행렬(Q), 키행렬(K), 벨류행렬(V)를 생성한다. 쿼리(Q), 키(K), 벨류(V) 행렬은 \(W^{Q}\), \(W^{K}\), \(W^{V}\)라는 3개의 가중치 행렬(weight matrix)을 생성한 다음 이 가중치 행렬을 입력행렬 (X)에 곱해 Q, K, V를 생성한다. \(W^{Q}\), \(W^{K}\), \(W^{V}\)는 처음에 임의의 값을 가지며, 학습 과정에서 최적을 값을 얻는다. 학습을 통해 최적의 가중치 행렬값이 생성되면 더욱 정확한 쿼리 값, 키값, 밸류 값을 얻게 된다.
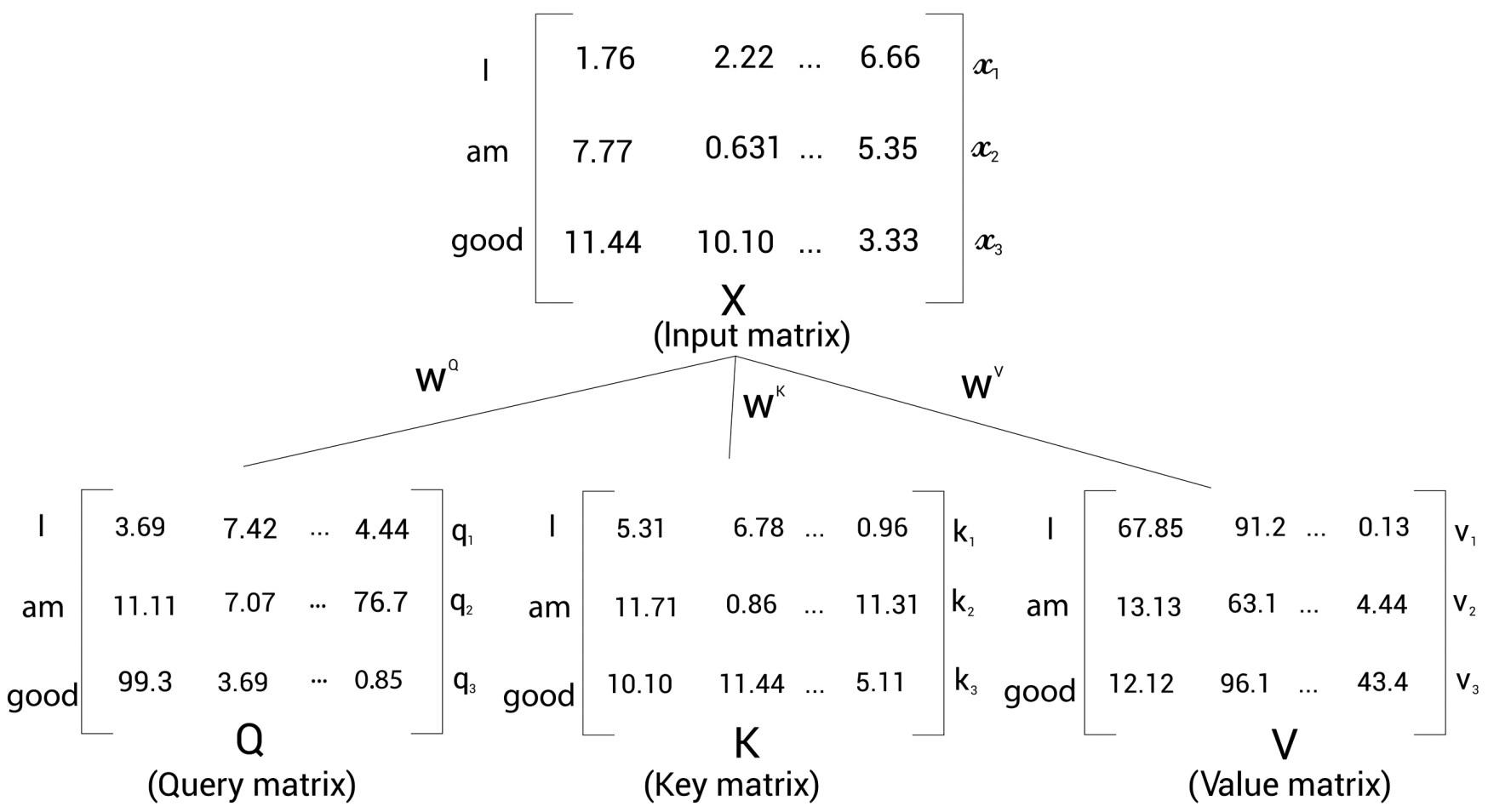
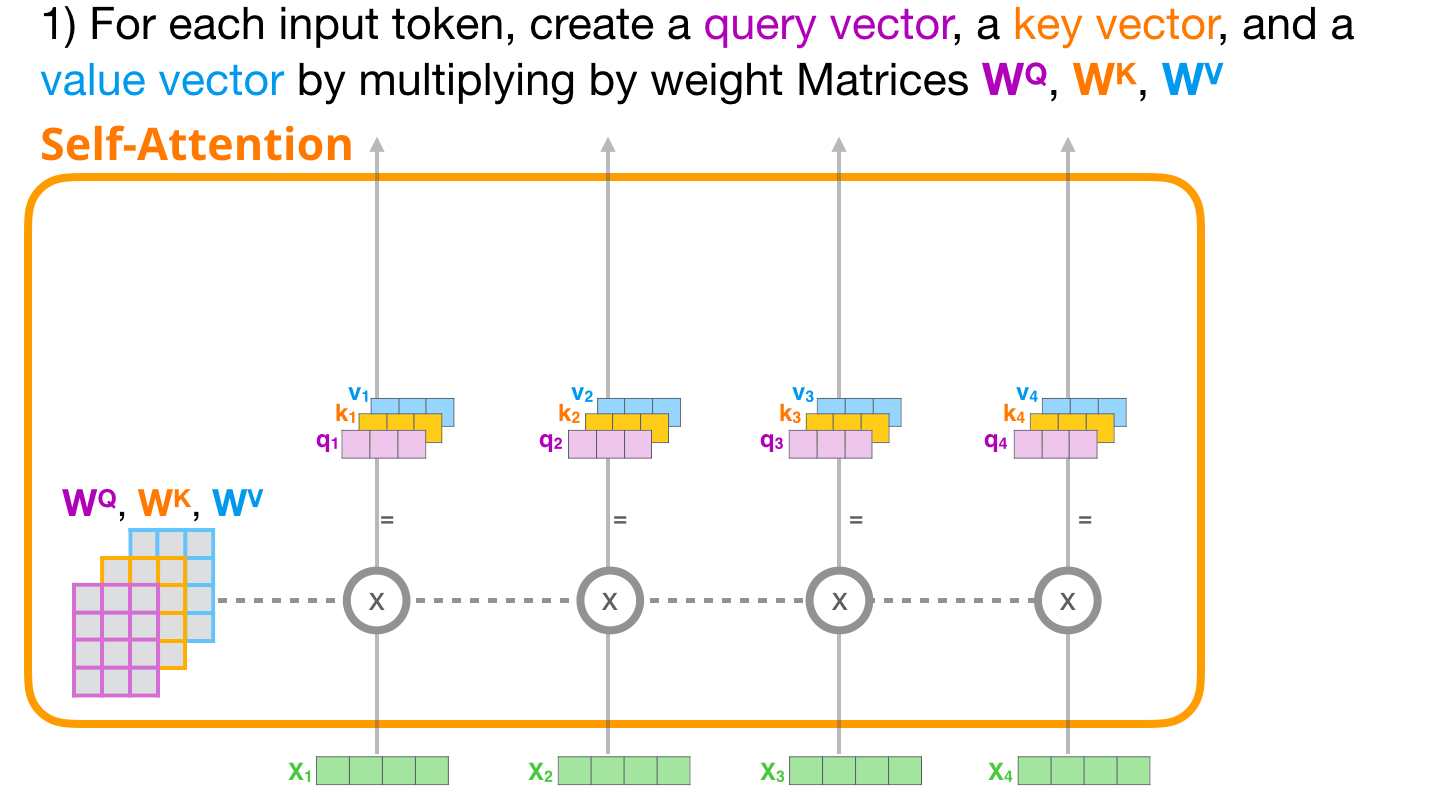
1단계:
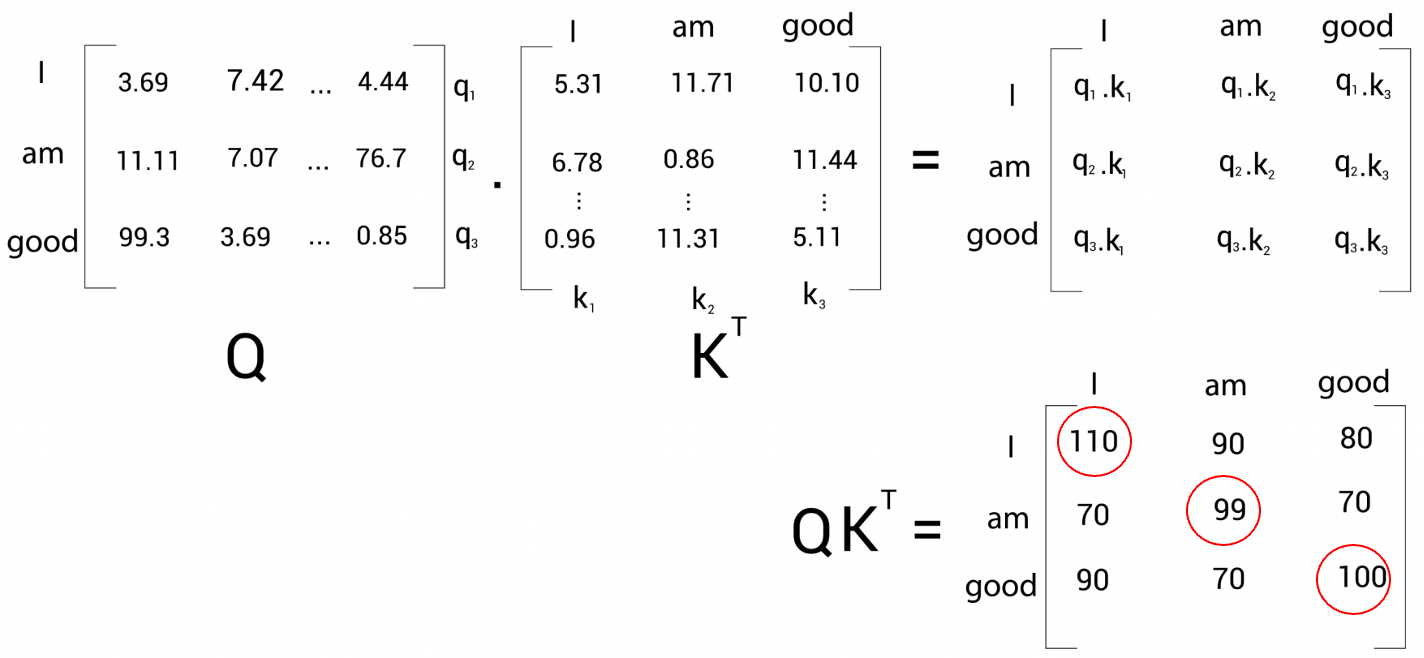
셀프 어텐션의 첫 번째 단계는 쿼리(Q) 행렬과 키\((K^{T}\)) 행렬의 내적 수행
쿼리 벡터 (\(q_{1}\)(I))와 키 벡터 (\(k_{1}\)(I), \(k_{2}\)(am), \(k_{3}\)(good)) 사이의 내적을 계산하는 것은 쿼리 벡터 \(q_{1}\)(I)과 키 벡터 \(k_{1}\)(I), \(k_{2}\)(am), \(k_{3}\)(good) 사이의 유사도를 계산한 것이다(→ 쿼리 행렬과 키 행렬 사이의 내적을 계산하면 유사도를 얻을 수 있다). 즉, \(Q·K^{T}\) 행렬의 첫 번 째행을 보면 내적 값을 기준으로 단어 'I'는 단어 'am'과 'good'보다 자신(I)과 연관성이 더 높은 것을 알 수 있다.
2단계:
Q·\(K^{T}\) 행렬을 키 벡터 차원의 제곱근 값으로 나누며, 그 결과 안정적인 경삿값(gradient)를 얻을 수 있다. 이 때 키 벡터의 차원은 64라고 가정.

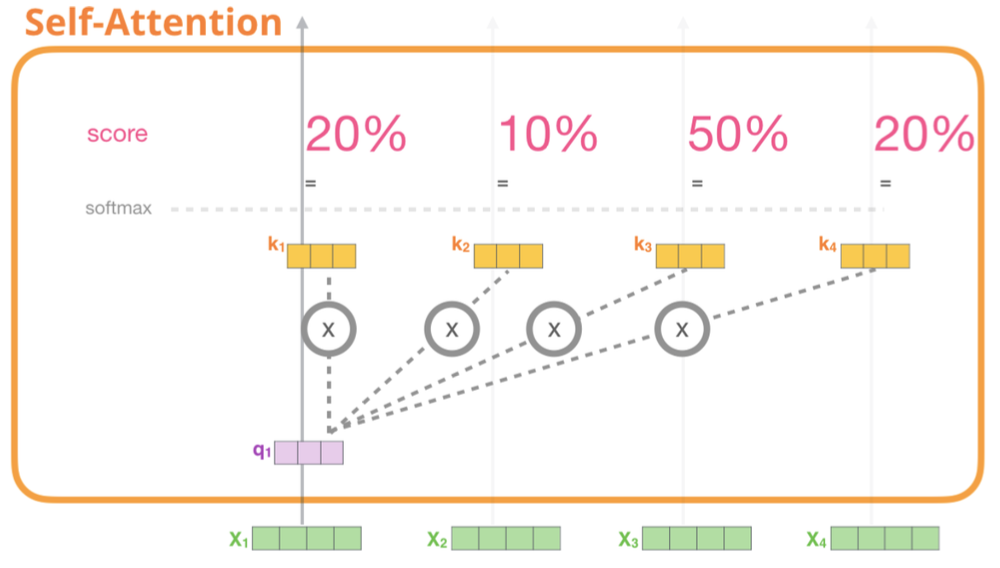
3단계:
Softmax 함수를 사용해 정규화 작업을 진행하며, 그 결과 전체 값의 합은 1이 되며 각각 0가 1사이의 값을 갖게된다.

이러한 행렬을 스코어 행렬이라고 한다. 위 점수를 바탕으로 문장 내에 있는 단어가 문장에 있는 전체 단어와 얼마나 연관되어 있는지 알수 있다. 예를 들어 스코어 행렬의 첫 행을 보면 단어 'I'는 자기 자신과 90%, 'am'과는 7% 'good'과는 3% 관련 되어 있다는 것을 알 수 있다.
4단계:


마지막 과정은 어텐션(Z)을 계산하는 것이다. 예를 들어 단어 'I'의 셀프 어텐션 \(z_{1}\)은 각 벨류 벡터값의 가중치 합으로 계산된다. 즉, \(z_{1}\)의 값은 벨류 벡터 \(v_{1}\)(I)의 90% 값과(→I는 \(v_{1}\)이 90% 반영) 벨류 벡터 \(v_{2}\)(am)의 7%값과(→I는 \(v_{2}\)가 7% 반영) 벨류 벡터 \(v_{3}\)(good)의 3% 값의(→I는 \(v_{3}\)가 3% 반영) 합으로 구한다.

*** 멀티헤드 어텐션 원리 ***
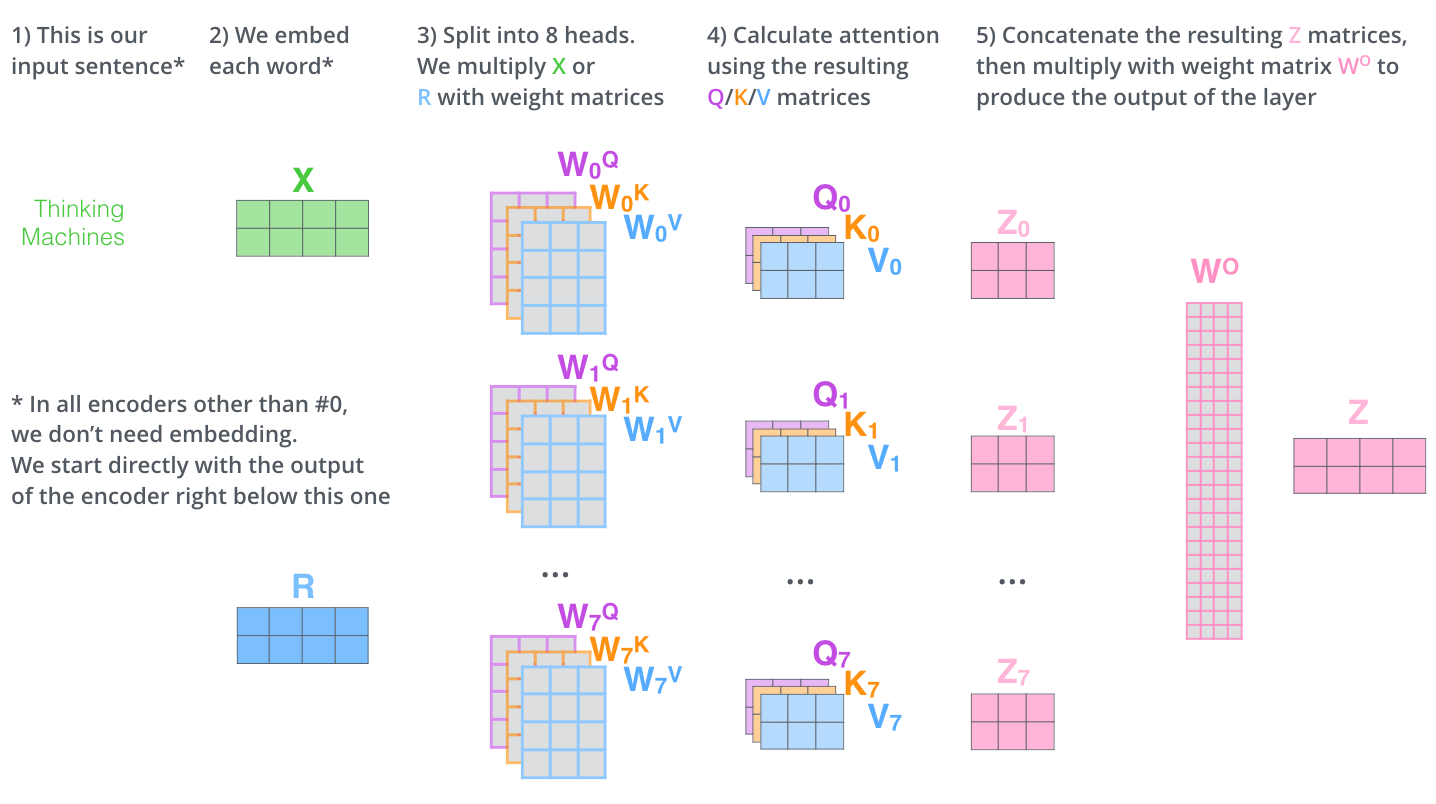
멀티 헤드 어텐션(multi-head attention)은 셀프 어텐션을 동시에 여러번 수행하는 걸 말한다. 여러 헤드가 독자적으로 셀프 어텐션을 계산하는 것이다.

어텐션 결과의 정확도를 높이기 위해서 단일 헤드 어텐션 행렬(single head attention)이 아닌 멀티 헤드 어텐션(multi-head attention)을 사용한 후 그 결괏값을 더하는 형태로 진행한다. 이와 같은 방법을 사용하는 데는 단일 헤드 어텐션을 사용하는 것보다 멀티 헤드 어텐션을 사용하면 좀 더 정확하게 문장의 의미를 이해할 수 있다는 가정이 깔려 있다. (* 헤드를 여러개 사용해 어텐션을 생성할 경우 단일 헤드를 사용하는 경우보다 오분류가 일어날 위험을 줄이는 것으로 해석할 수 있다.)
멀티 헤드 어텐션 = concatenate(\(Z_{1}\), \(Z_{2}\), \(Z_{3}\), ..., \(Z_{8}\))·\(W_{0}\) (→ 2X24 * 24X3)
어텐션 헤드의 최종 결과는 어텐션 헤드의 원래 크기이므로 크기를 줄이기 위해 가중치 행렬값(\(W_{0}\))을 곱하는 것이다.

2.6. 위치 인코딩(Positional Encoding)
RNN에서는 단어 단위로 네트워크에 문장을 입력한다. 예를 들어 I am good이라는 문장이 있을 때 처음에 'I'라는 단어가 입력으로 전달된 다음에 'am'이 라는 단어가 전달된다. 하지만 트랜스포머 네트워크에서는 위와 같은 순환 구조를 따르지 않는다. 단어 단위로 문장을 입력하는 대신에 문장 안에 있는 모든 단어를 병렬 형태로 입력한다. 즉, 한꺼번에 모든 단어를 처리하기 때문에 위치정보가 유지되지 못해 위치 인코딩이 필요하다.
따라서, 단어의 위치 정보를 제공하기 위해 위치 인코딩을 수행한다. 입력 행렬을 트랜스포머에 직접 전달하는 대신 네트워크에서 문장의 의미를 이해할 수 있도록 단어의 순서(단어의 위치)를 표현하는 정보를 추가로 제공한다. (X는 입력행렬 or 입력 임베딩, P는 위치 인코딩)

2.7. 트랜스포머 디코더 계산 수행
* 영어(입력 문장) 'I am good'을 입력하면 프랑스어(타깃 문장) 'Je vais bien'을 생성하는 번역기를 만든다고 가정
- 인코더의 입력 문장 표현(인코더의 출력값, Representation)이 모든 디코더에 전송된다. 즉, 디코더는 이전 디코더의 입력값과 인코더의 표현(인코더의 출력값) 2개를 입력 데이터로 받는다.
- 시간 스텝 t=1이라면 디코더의 입력은 문장의 시작을 알리는 <sos>를 입력받고 타깃 문장으로 첫 번째 단어인 'Je'를 생성한다.
- 시간 스텝 t=2 경우 현재까지의 입력값에 이전 단계(t-1)에서 생성한 단어를 추가해 문장의 다음 단어를 생성한다. 즉 디코더는 <sos>와 'Je'를 입력받아 타깃 문장의 다음 단어를 생성한다.
- 이러한 방식으로 디코더에서 <eos> 토큰을 생성할 때 타깃 문장의 생성이 완료 된다.
- 디코더는 인코더와는 다르게 마스크 된 멀티 헤드 어텐션(masked multi-head attention)을 사용한다.


모델을 학습할 때는 이미 타깃 문장을 알고 있어서 디코더에 기본으로 타깃 문장 전체를 입력하면 되나 수정이 필요하다. 디코더에서 문장을 입력할 때 처음에는 <sos> 토큰을 입력하고 <eos> 토큰이 생성될 때까지 이전 단계에서 예측한 단어를 추가하는 형태로 입력을 반복한다.
'I am good'을 'Je vais bien'으로 번역한다고 가정할 때 타깃 문장 시작 부분에 <sos> 토큰을 추가한 '<sos> Je vais bien'을 디코더에 입력하면 디코더에서 'Je vais bien <eos>'를 출력한다.

디코더의 입력 문장은 '<sos> Je vais bien'이다. 셀프 어텐션은 각 단어의 의미를 이해하기 위해 각 단어와 문장 내 전체 단어를 연결했었다. 그런데 디코더에서 문장을 생성할 때 이전 단계에서 생성한 단어만 입력 문장으로 넣는다는 점이 중요하다. 예를 들어 t=2의 경우 디코더의 입력 단어는 [<sos>, Je]만 들어간다. 즉, t=2에서 셀프 어텐션은 단어와의 연관성을 'Je'만 고려해야 하며, 모델이 아직 예측하지 않은 오른쪽의 모든 단어를 마스킹해 학습을 진행한다. 위와 같은 단어 마스킹 작업은 셀프 어텐션에서 입력되는 단어에만 집중해 단어를 정확하게 생성하는 긍정적 효과를 가져온다.

또한, 멀티 헤드 어텐션을 계산하면 h개의 쿼리, 키, 밸류 행렬을 생성한다. 따라서 헤드 i의 경우 행렬 X에 각각 가중치 행렬 \(W^{Q}_{i}\), \(W^{K}_{i}\), \(W^{V}_{i}\)를 곱해 쿼리(\(Q_{i}\)), 키(\(K_{i}\)), 밸류(\(V_{i}\)) 행렬을 얻을 수 있다.
i 헤드의 어텐션 행렬 \(Z_{i}\)는 다음 식으로 구할 수 있다. (i는 헤드 넘버)
$$ Z_{i} = softmax(\frac{Q_{i}K_{i}^{T}}{\sqrt{d_{k}}})V_{i} $$
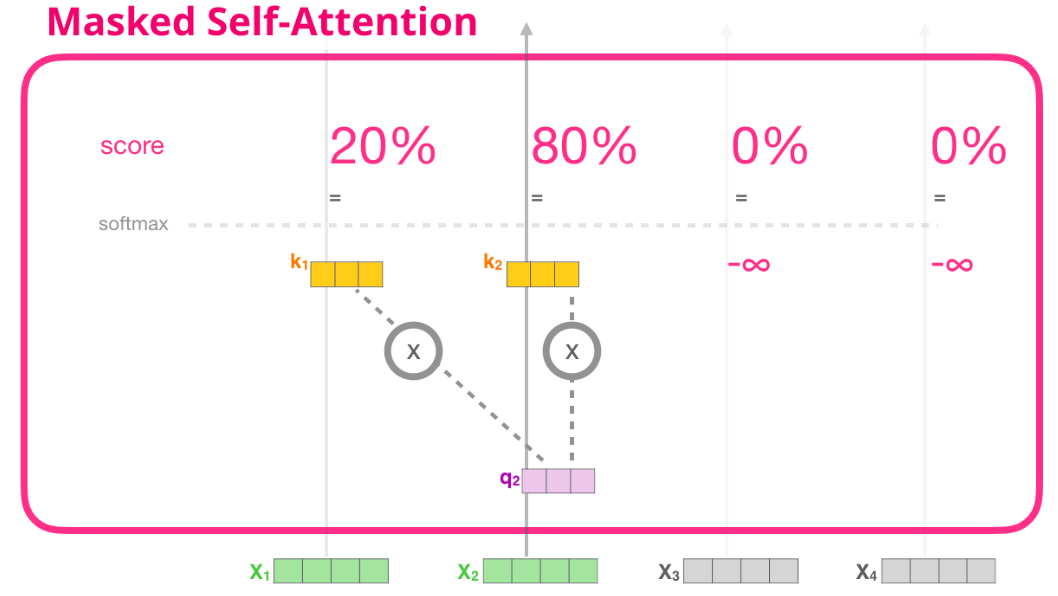
위 계산 과정에서 소프트맥스 함수를 적용하기 전에 행렬값에 대한 마스킹 처리가 필요하다. 예를 들어 <sos>의 다음 단어를 예측한다고 할 때 모델에서는 <sos> 오른쪽에 있는 모든 단어를 참조하지 말아야 한다. 따라서 <sos> 오른쪽에 있는 모든 단어를 -∞로 마스킹을 수행한다. 즉, 마스킹은 소프트맥스 확률이 0이 되도록 하여, 밸류와의 가중합에서 해당 단어 정보들이 무시되게끔 하는 방식으로 수행된다.
★ (모델 학습의 경우) 이러한 마스킹 과정을 순서대로 할 필요없이 한꺼번에 수행할 수 있다(Do not need to be done sequentially, but can be done at one batch). 즉, 'robot must obey orders'라는 문장을 학습하기 위해 순서대로(sequential) 4번의 마스킹 계산을 수행할 필요없이 한 번에(batch) 마스킹 처리하여 loss를 구할 수 있다.


이후 소프트맥스 함수를 적용한 행렬과 밸류(\(V_{i}\)) 행렬에 곱해 최종적으로 어텐션 행렬(\(Z_{i}\))을 구한다. 멀티 헤드 어텐션의, 경우 h개의 어텐션 행렬을 구하고 서로 연결한 다음 새로운 가중치 행렬 \(W^{0}\)을 곱해 최종적으로 어텐션 행렬 M을 구한다.
$$ M = concatenate(Z_{1}, Z_{2}, Z_{3}, ..., Z_{h})W_{0} $$
2.8. 디코더 멀티 헤드 어텐션(인코더-디코더 어텐션 레이어, encoder-decoder attention layer)
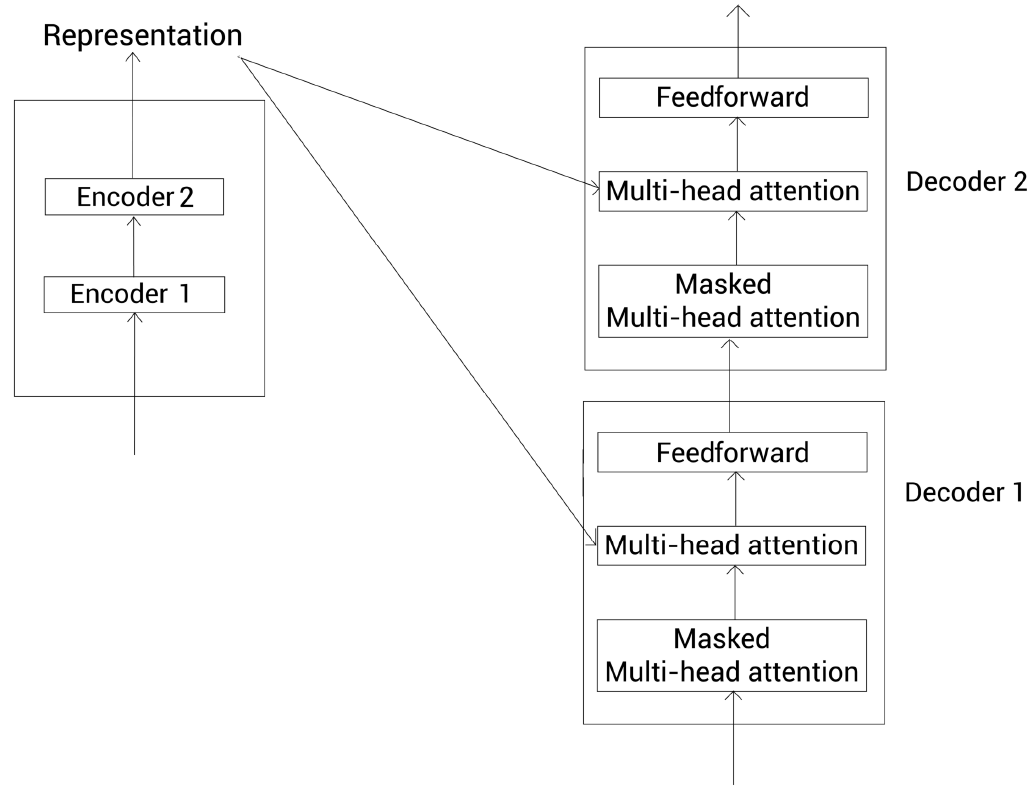
- 디코더의 멀티 헤더 어텐션은 이전 서브레이어의 출력값 및 인코더의 표현 2개의 입력데이터를 받는다.
- 이 때 인코더의 표현 값을 R, 이전 서브레이어의 마스크 된 멀티 헤드 어텐션 결과로 나온 어텐션 행렬을 M이라고 할 때 두 결과의 상호작용이 일어나며 이것을 인코더-디코더 어텐션 레이어(encoder-decoder attention layer)라고 부르며 동작 방법은 다음과 같다. (i는 개별적인 헤더의 갯수).
- 이전 서브레이어의 출력값인 어텐션 행렬 M을 사용해 쿼리 행렬 Q를 생성하고, 인코더 표현 값인 R을 활용해 키(K), 밸류(V) 행렬을 생성한다.
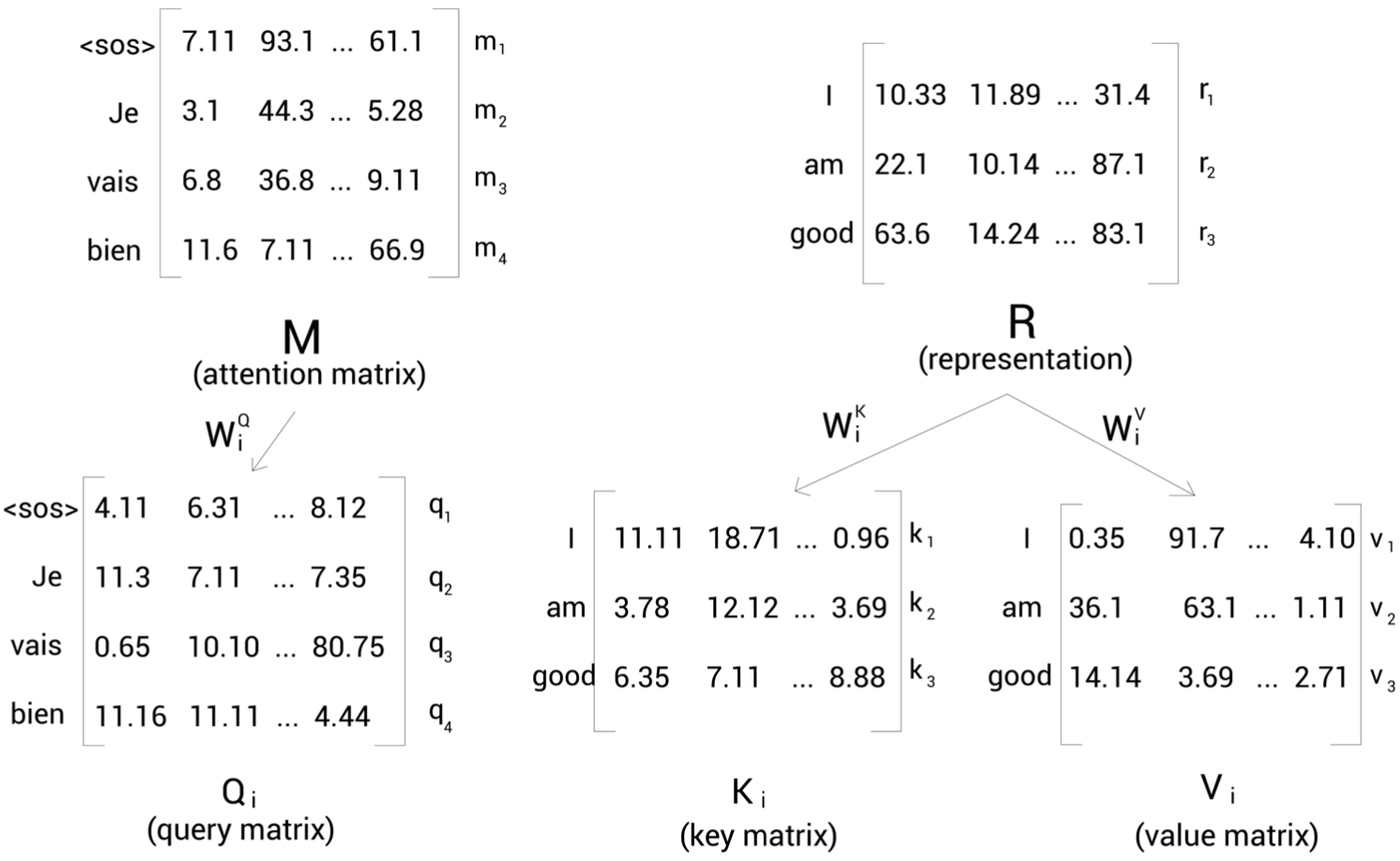
이후 계산은 앞서 인코더에서 수행한 셀프어텐션과 동일하게 진행된다.
추가로 행렬 \(Q_{i}\)· \(K^{T}_{i}\)의 내적 계산을 통해 다음의 사실을 파악할 수 있다.
- 행렬의 첫 번째 행에서 쿼리 벡터 q1(<sos>)와 모든 키 벡터 \(k_{1}\)(I), \(k_{2}\)(am), \(k_{3}\)(good) 사이의 내적을 계산하는 것은 내적의 결과로 나온 첫 번째행은 타깃 단어 <sos>가 입력 문장의 모든 단어 (I, am, good)와 얼마나 유사한지를 계산하는 것으로 이해할 수 있다.
- 즉, 쿼리행렬(타깃 문장 표현)과 키 행렬 (입력 문장 표현) 간의 유사도를 계산할 수 있다.

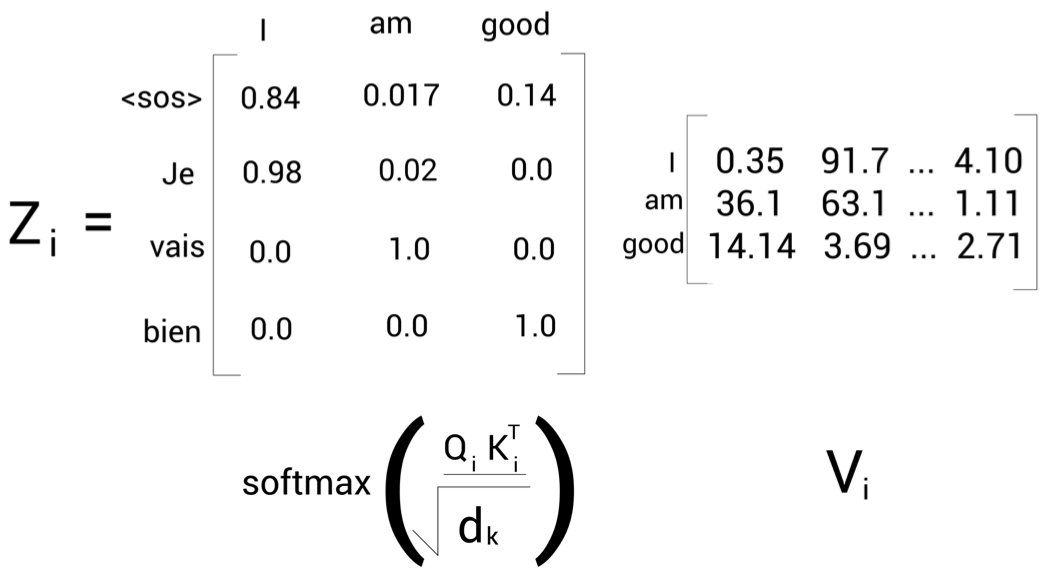

\(z_{2}\)는 98%는 벡터값 \(v_{1}\)(I)와 2%의 벡터값 \(v_{2}\)(am)을 포함한다. 모델에서 타깃 단어 'Je'가 입력 단어 'I'를 의미한다고 해석할 수 있다. 이후 디코더가 타깃 문장에 대한 표현을 학습시키면 최상위 디코더에서 얻은 출력 값을 선형 및 소프트맥스 레이어에 전달한다.
2.9. Residual and layer-nomarlization
각 인코더 및 디코더의 하위 계층(셀프 어텐션, FFN)은 학습 성능을 끌어 올리기 위해 잔차연결(residual connection) 및 층 정규화(layer-normalization)를 수행한다.

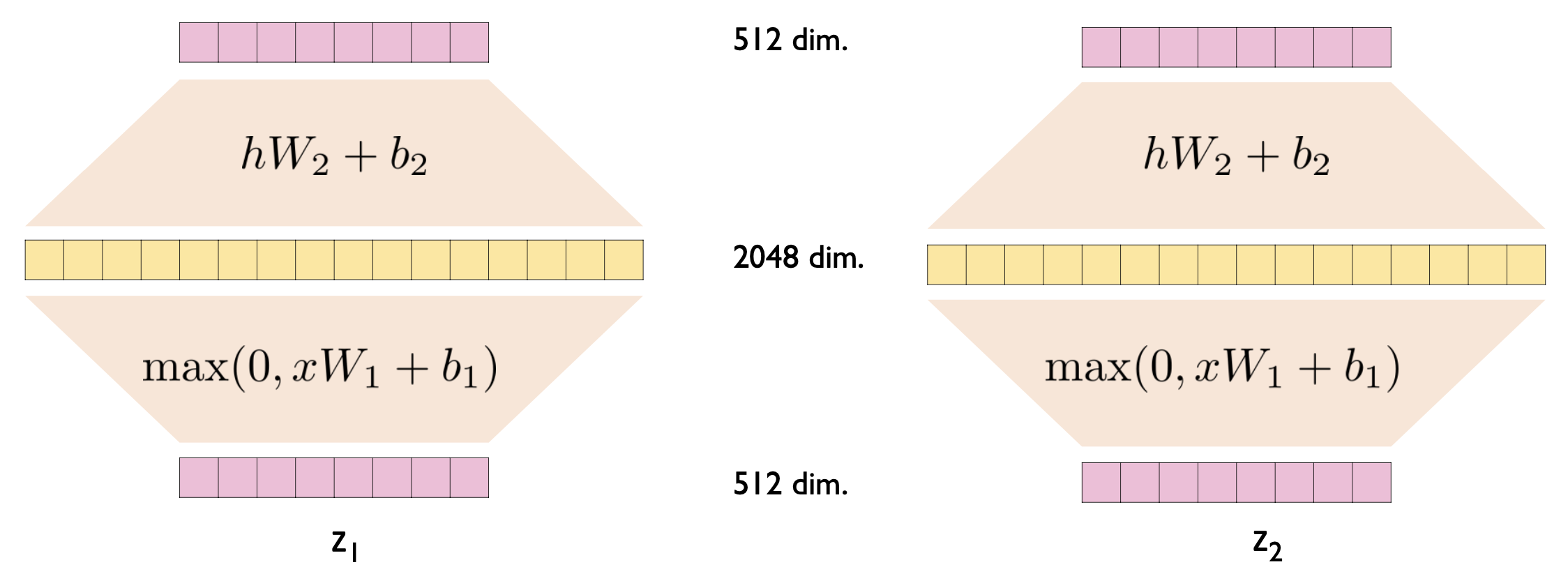
2.10. Position-wise Feed-Forward Networks
Fully connected Feed-Forward Network는 토큰 각각 개별적으로(seperately) 동일하게(identically) 적용된다. 다만, 레이어마다 서로 다른 매개변수를 사용한다(\(W_{1}\)과 \(W_{2}\)의 매개변수 값이 다르다).
$$ FFN(x) = max(0,xW_{1} + b_{1})W_{2} + b_{2} $$

2.11. The Final Linear and Softmax Layer
- 선형 레이어: 디코더 스택에 의해 생성된 벡터를 로짓 벡터라고 하는 훨씬 더 큰 벡터로 투영하는 완전 연결 신경망
- 소프트맥스 레이어: 가장 높은 확률을 가진 셀의 인덱스가 선택되고(argmax) 그와 관련된 단어가 최종적으로 출력

References:
[1] BERT와 GPT로 배우는 자연어 처리, 이지스 퍼블리닝, 이기창
[2] ratsgo's NLP blog, https://ratsgo.github.io/nlpbook/docs/language_model/transformers/
[3] 구글 BERT의 정석, 한빛미디어
[4] Getting Started with Google BERT: Build and train state-of-the-art natural language processing models using BERT
[5] 고려대학교 강필성 교수님 유튜브 강의, https://www.youtube.com/watch?v=Yk1tV_cXMMU
'GPT > 개념정의' 카테고리의 다른 글
| BERT(Bidirectional Encoder Representation from Transformer) (0) | 2022.10.25 |
|---|---|
| GPT(Generative Pre-trained Transformer) Overview (0) | 2022.10.25 |
| 서브워드 토크나이저(Subword Tokenizer) (0) | 2022.04.24 |
| 토큰화(Tokenization) (0) | 2022.04.22 |
| 워드임베딩(Word embedding)과 워드투벡터(Word2Vec) (0) | 2022.04.11 |



