
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- cnn
- 챗GPT
- 설명가능성
- Ai
- 트랜스포머
- ML
- 지피티
- 신뢰성
- 케라스
- ChatGPT
- AI Fairness
- XAI
- Transformer
- gpt2
- GPT
- Tokenization
- 인공지능
- GPT-3
- nlp
- Bert
- 딥러닝
- trustworthiness
- MLOps
- word2vec
- DevOps
- 인공지능 신뢰성
- 자연어
- 머신러닝
- fairness
- 챗지피티
- Today
- Total
research notes
BERT(Bidirectional Encoder Representation from Transformer) 본문
BERT(Bidirectional Encoder Representation from Transformer)
forest62590 2022. 10. 25. 21:44
BERT는 구글에서 발표한 최신 임베딩 모델이며 트랜스포머를 이용하여 구현되었다. 또한, 위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델이다.
BERT가 높은 성능을 얻을 수 있었던 것은, 레이블이 없는 방대한 데이터로 사전 훈련된 모델을 가지고, 레이블이 있는 다른 작업(Task)에서 추가 훈련과 함께 하이퍼파라미터를 재조정하여 이 모델을 사용하면 성능이 높게 나오는 기존의 사례들을 참고하였기 때문이다. 다른 작업에 대해서 파라미터 재조정을 위한 추가 훈련 과정을 파인 튜닝(Fine-tuning)이라고 한다.
아래 그림은 BERT의 파인 튜닝 사례를 보여준다. 우리가 하고 싶은 태스크가 스팸 메일 분류라고 하였을 때, 이미 위키피디아 등으로 사전 학습된 BERT 위에 분류를 위한 신경망을 한 층 추가한다. 이 경우, 비유하자면 BERT가 언어 모델 사전 학습 과정에서 얻은 지식을 활용할 수 있으므로 스팸 메일 분류에서 보다 더 좋은 성능을 얻을 수 있다.

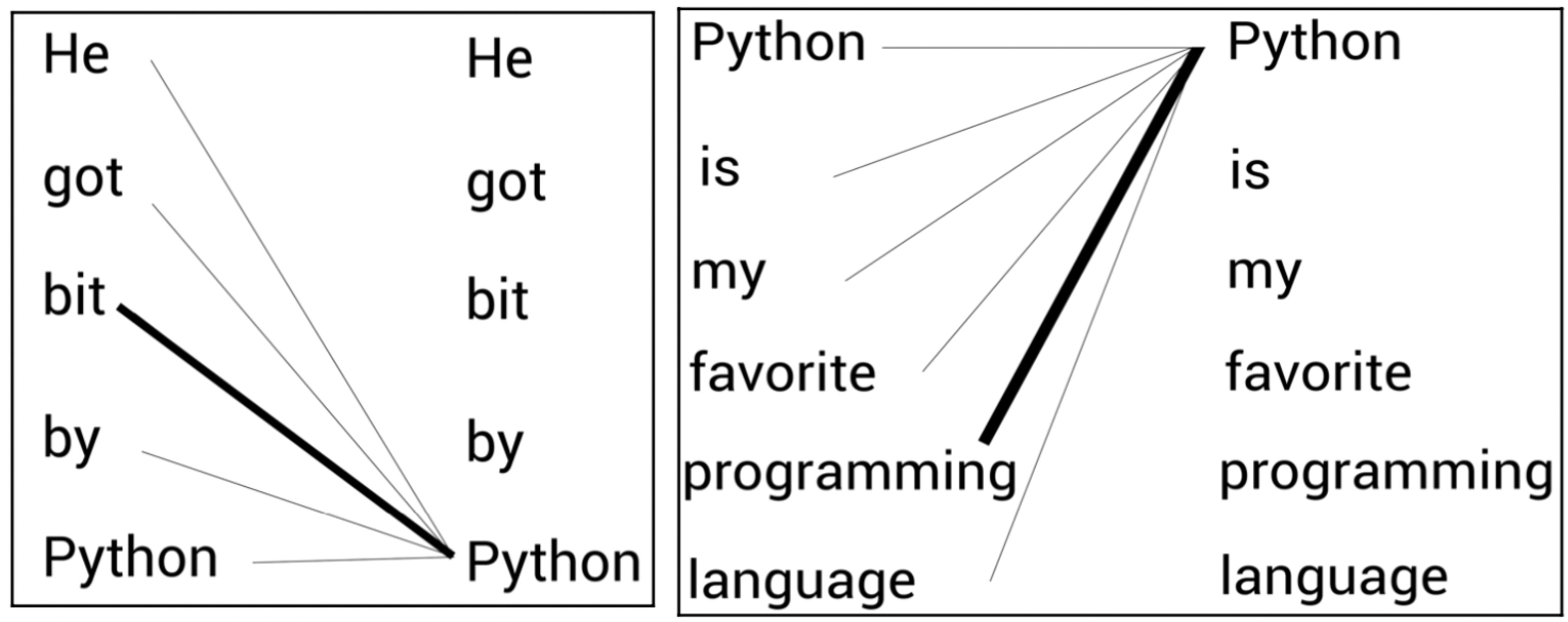
BERT의 주된 성공 이유는 문맥(context)을 고려하지 않는(context-free) 워드투벡터(word2vec)와 같은 다른 인기 있는 임베딩 모델과 달리 문맥을 고려한(context-based) 임베딩 모델이기 때문이다.
예를 들어,
A문장: He got bit by a python.
B문장: Python is my favorite programming language.
위 두 문장이 있을 때 BERT는 모든 단어의 문맥상 의미를 이해하기 위해 문장의 각 단어를 문장의 다른 모든 단어와 연결시켜 이해한다. A문장의 경우 'python'이라는 단어는 'bit'이라는 단어와 강한 연결을 가져 pyhton이 뱀의 한 종류를 의미한다는 걸 파악하고, B문장의 경우는 'python'이 'programming'과 강한 연관이 있음을 파악해 단어의 의미를 이해한다. 즉, 같은 단어라도 문맥에 따라 다른 단어 임베딩을 생성한다.
1. BERT의 구조
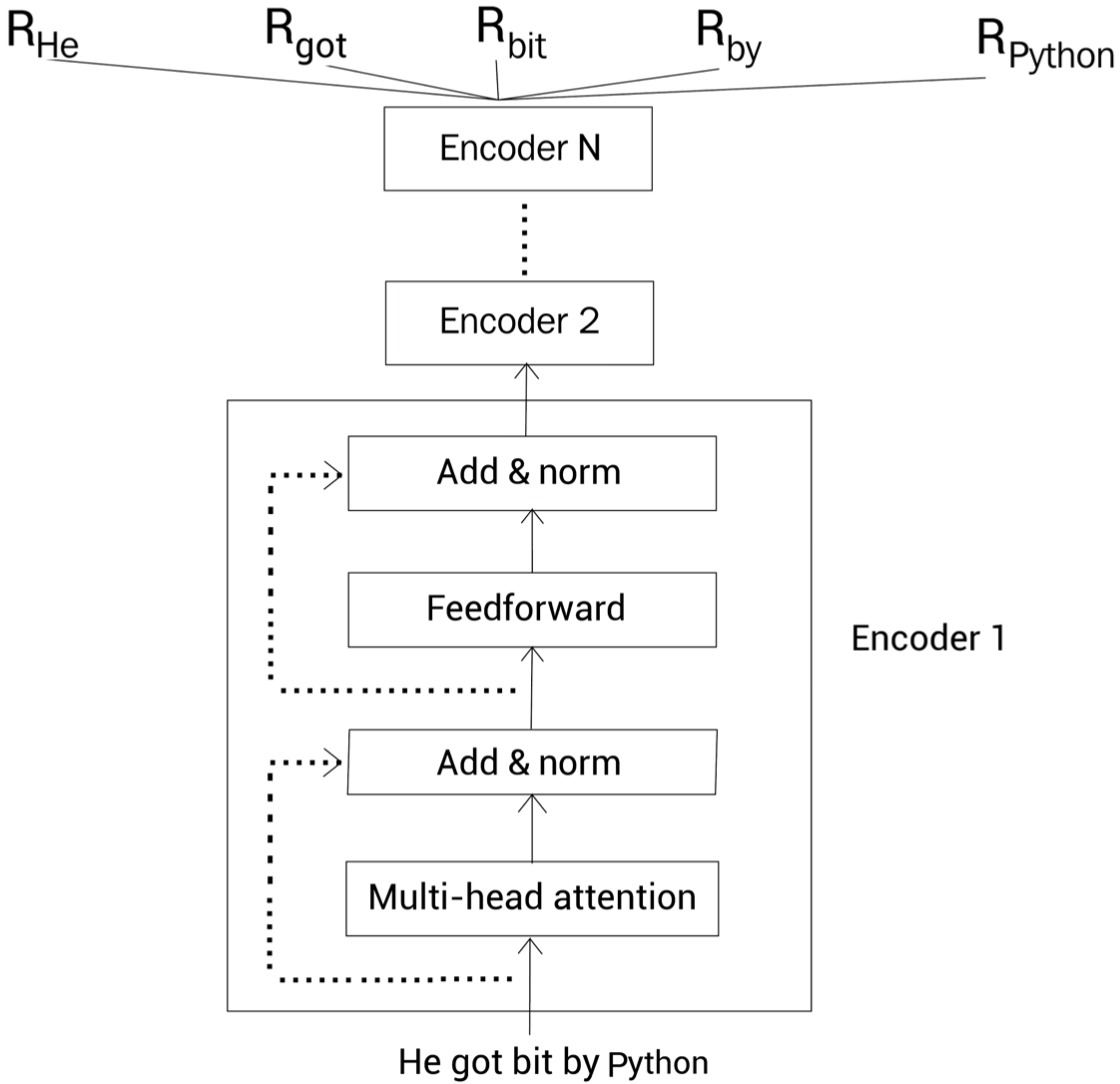
BERT는 트랜스포머 모델을 기반으로 하며 인코더-디코더가 있는 트랜스포머 모델과 달리 인코더만 사용한다.
- 인코더 레이어의 수: L
- 어텐션 헤드: A
- 은닉 유닛: H
라고 할 때 BERT-base, BERT-large와 같은 표준 구조 외에도 다른 조합으로 BERT를 구축할 수 있다.
BERT-base: L=12, A=12, H=768
BERT-large: L=24, A=16, H=1204
BERT-tiny: L=2, A=2, H=128
BERT-mini: L=4, A=4, H=256
BERT-small: L=4, A=8, H=521
BERT-medium: L=8, A=8, H=521

2. BERT의 입력표현
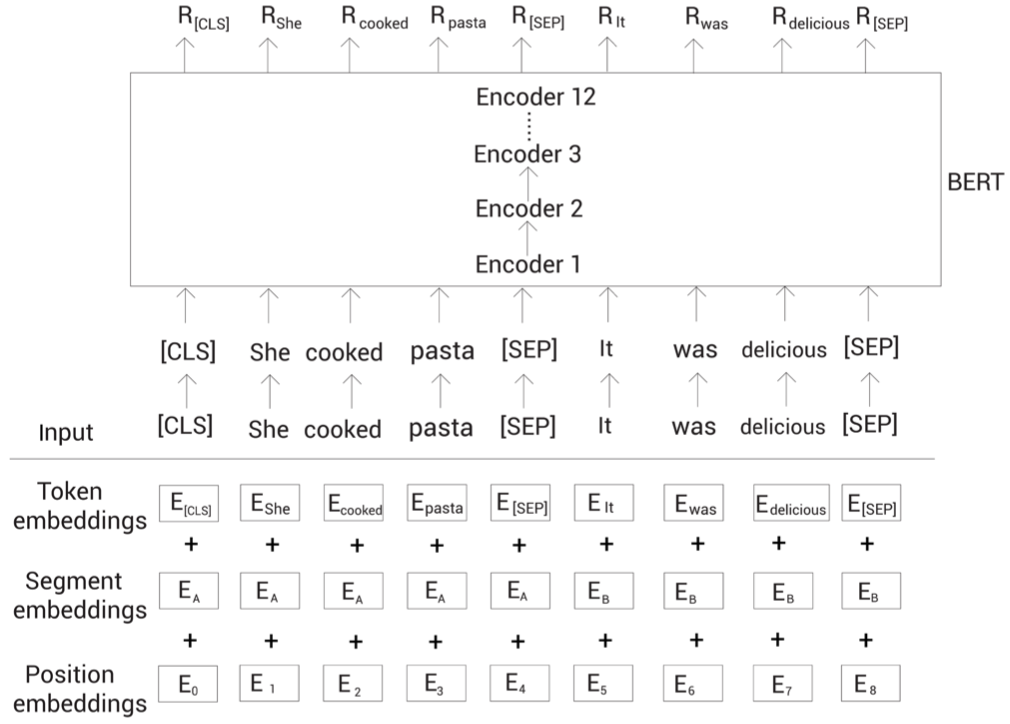
① BERT에 데이터를 입력하기 전에 아래 세 가지 임베딩을 수행해야 한다.
- 토큰 임베딩(token embedding): [CLS], [SEP] 등의 스페셜 토큰을 활용해 입력 문장을 재구성해 토큰화 하고 토큰 임베딩으로 변환한다. 토큰 임베딩의 변수들은 사전 학습이 진행되면서 학습된다. BERT에서는 워드피스 토큰화 결과로 생성된 30,000개의 토큰을 가진 어휘 집합을 사용한다.
- [CLS] 토큰: 문장의 시작 부분에 추가, 분류 작업에 사용
- [SEP] 토큰: 모든 문장의 끝에 추가, 모든 문장의 끝을 나타내는 데 사용
- 세그먼트 임베딩(segment embedding): 주어진 두 문장을 구별하는데 사용한다. [SEP] 토큰과 별도로 두 문장을 구분하기 위해 모델에 일종의 지표를 제공한다.
- 위치 임베딩(positional embedding): 트랜스포머가 어떤 반복 매커니즘도 사용하지 않고 모든 단어를 병렬로 처리하므로 단어 순서와 관련된 정보를 제공하기 위해 사용된다.

② 워드피스 토크나이저
- BERT는 워드피스 토크나이저를 사용하며 하위 단어(subword) 토큰화 알고리즘을 기반으로 한다.
예) Let us start pretraining the model
tokens=[Let, us, start, pre, ##train, ##ing, the, model]
워드피스 토크나이저는 토큰화 할 때 어휘 사전에 단어가 있으면 그 단어를 토큰으로 사용하고, 없으면 그 단어를 하위 단어로 분할해 하위 단어가 어휘 사전에 있는지 확인하고 있으면 토큰화 한다. 즉, 어휘 사전에 있으면 토큰으로 사용하고 그렇지 않으면 하위 단어로 분할하고 확인하는 반복적인 작업을 수행한다.
pretraining이라는 단어는 BERT의 어휘 사전에 없기 때문에 pre, ##train, ##ing와 같은 하위 단어로 나누고 ##train, ##ing 앞의 # 기호는 앞에 다른 단어가 있음을 의미한다. 이 때 어휘 사전에 ##train과 ##ing가 존재하기 때문에 다시 나누지 않고 토큰화한다.
위와 같은 토큰화 과정을 수행 후 문장 시작 부분에 [CLS] 토큰과 끝 부분에 [SEP] 토큰을 추가하고 앞서 언급한 세 가지 임베딩 과정을 수행한다.
* tokens=[ [CLS], let, us, start, pre, ##train, ##ing, the, model, [SEP] ]
- 모든 sentence의 첫번째 token은 언제나 [CLS](special classification token)이다. 이 [CLS] token은 transformer 전체층을 다 거치고 나면 token sequence의 결합된 의미를 가지게 되는데, 여기에 간단한 classifier를 붙이면 단일 문장, 또는 연속된 문장의 classification을 쉽게 할 수 있게 된다. 만약 classification task가 아니라면 이 token은 무시하면 된다.
3. BERT 사전 학습전략
BERT는 마스크 언어 모델링(Masked Language Modeling, MLM), 다음 문장 예측 (Next Sentence Prediction, NSP) 두 가지 태스크로 사전학습을 수행한다.
① 언어 모델링(Language modeling):
언어 모델링은 일반적으로 임의의 문장이 주어지고 단어를 순서대로 보면서 다음 단어를 예측하도록 모델을 학습 시키는 것을 말하며 크게 자동 회귀 언어 모델링(auto-regressive language modeling)과 자동 인코딩 언어 모델링(auto-encoding language modeling) 두 가지로 분류할 수 있다.
□ 자동 회귀 언어 모델링(단방향):
자동 회귀 언어 모델링에는 전방예측(left-to-right prediction)과 후방예측(right-to-left prediction) 두 가지 방식이 있다.
ex) Paris is a beautiful _. I love Paris.
전방예측은 Paris is a beautiful _. 을 이용하여 예측을 수행하고, 후방 예측은 _. I love Paris.을 이용해 예측을 수행한다.
□ 자동 인코딩 언어 모델링(양방향, BERT):
자동 인코딩 언어 모델링은 전방 및 후방 예측을 모두 활용한다. 양방향으로 문장을 읽으면 문장 이해 측면에서 더 명확해지므로 더 정확한 결과를 제공할 수 있다.
ex) Paris is a beautiful _. I love Paris.
② 마스크 언어 모델링(MLM, 빈칸 채우기 태스크):
- BERT는 자동 인코딩 언어 모델로, 예측을 위해 문장을 양방향으로 읽는다.
- BERT는 입력을 받은 다음 각 토큰의 표현 벡터를 출력으로 반환한다. R[CLS]는 [CLS] 토큰의 표현 벡터를 의미하며, R_Paris는 Paris 토큰의 표현 벡터를 의미한다.
- BERT-base 모델을 사용할 경우 768개의 은닉 유닛이 사용되므로 각 토큰의 표현 벡터 크기는 768이 된다.
- 아래 그림과 같이 마스크 된 토큰 R[MASK]의 표현을 피드포워드+소프트맥스 네트워크에 전달하면, R[MASK]에 위치할 가장 적합한 단어에 대한 확률분포를 확인 할 수 있다. 따라서 'city'라는 단어가 마스크 된 단어일 확률이 높다.


예시를 통해 이해해보자. 'My dog is cute. he likes playing'이라는 문장에 대해서 마스크드 언어 모델을 학습하고자 한다. 약간의 전처리와 BERT의 서브워드 토크나이저에 의해 이 문장은 ['my', 'dog', 'is' 'cute', 'he', 'likes', 'play', '##ing']로 토큰화가 되어 BERT의 입력으로 사용된다. 그리고 언어 모델 학습을 위해서 'dog' 토큰이 [MASK]로 데이터가 변경 되었다고 가정한다.

위 그림은 'dog' 토큰이 [MASK]로 변경되어서 BERT 모델이 원래 단어를 맞추려고 하는 모습을 보여준다. 여기서 출력층에 있는 다른 위치의 벡터들은 예측과 학습에 사용되지 않고, 오직 'dog' 위치의 출력층의 벡터만이 사용된다. 구체적으로는 BERT의 손실 함수에서 다른 위치에서의 예측은 무시한다. 출력층에서는 예측을 위해 단어 집합의 크기만큼의 밀집층(Dense layer)에 소프트맥스 함수가 사용된 1개의 층을 사용하여 원래 단어가 무엇인지를 맞추게 된다.
③ 다음 문장 예측(NSP):
BERT에 두 문장을 입력하고 두 번째 문장이 첫 번째 문장의 다음 문장인지 예측하는 이진 분류이다.
예를 들어,
Set1 → A: She cooked pasta. B: It was delicious.
위 문장에서 B문장은 A문장의 후속 문장이다. 따라서 이 문장 쌍을 isNext로 표시해 B문장이 A문장의 다음 문장임을 알 수 있게 한다.
Set2 → A: Turn the radio on. B: She bought a new hat.
이 문장 쌍에서 B문장은 A문장의 후속 문장이 아니다. 따라서 이 문장 쌍을 notNext로 표시해 B문장이 A문장의 다음 문장이 아님을 알 수 있게 한다.
NSP 태스크를 수행함으로써 모델은 두 문장 사이의 관계를 파악할 수 있으며, 두 문장 간의 관계를 이해하는 것은 질의응답 및 유사문장탐지와 같은 다운스트림 태스크에서 유용하다. 분류를 수행하려면 간단히 [CLS] 토큰 표현을 가져와 소프트맥스 함수를 사용해 프드포워드 네트워크에 입력한다. 그러면 문장 쌍이 isNext인지, notNext인지에 대한 확률값이 반환된다.

4. BERT 활용하기
BERT를 처음부터 사전에 학습시키는 것은 계산 비용이 많이든다. 따라서 사전 학습 된 공개 BERT 모델을 다운로드해 사용하는 것이 효과적이다. 구글은 사전 학습된 다양한 BERT 모델을 오픈소스로 제공하고 있다(https://github.com/google-research/bert). 또한, 사전 학습된 BERT 모델을 문서(텍스트) 분류, 자연어 추론, 개채명 인식, 질문-응답 등과 같은 다운스트림 태스크에 맞게 파인튜닝하여 다양하게 사용할 수 있다.

References:
[1] 구글 BERT의 정석, 한빛미디어
[2] https://tmaxai.github.io/post/BERT/
[3] 딥 러닝을 이용한 자연어 처리 입문, 위키독스, https://wikidocs.net/115055
'GPT > 개념정의' 카테고리의 다른 글
| How GPT-2 and GPT-3 works? (0) | 2023.02.26 |
|---|---|
| GPT 다음 토큰 선택 알고리즘 (1) | 2022.11.05 |
| GPT(Generative Pre-trained Transformer) Overview (0) | 2022.10.25 |
| 트랜스포머(Transformer) (0) | 2022.04.24 |
| 서브워드 토크나이저(Subword Tokenizer) (0) | 2022.04.24 |



