
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 설명가능성
- ChatGPT
- 챗지피티
- Tokenization
- ML
- 케라스
- GPT-3
- 신뢰성
- AI Fairness
- 머신러닝
- word2vec
- MLOps
- Transformer
- 딥러닝
- nlp
- 자연어
- 트랜스포머
- 챗GPT
- gpt2
- 인공지능
- cnn
- Bert
- 인공지능 신뢰성
- XAI
- DevOps
- GPT
- trustworthiness
- Ai
- fairness
- 지피티
- Today
- Total
research notes
GPT(Generative Pre-trained Transformer) Overview 본문

GPT-1: Generative Pre-Training of a Language Model
1. 연구배경
보통 NLP 관련 데이터 셋은 Labeled 데이터 세트 보다 Unlabeled 형태의 데이터 셋이 훨씬 많다. 즉, 언어 모델을 학습하는데 필요한 데이터의 활용측면에 있어 레이블 된 데이터와 그렇지 않은 학습데이터 수의 차이가 상당하다. 따라서, Unlabeled 데이터 셋을 이용해 학습을 한 후 이를(Pre-trained model) 활용해 특정 태스크에 대한 학습을 수행하면(레이블 된 데이터를 활용해) 더 좋은 성능을 가진 모델을 만들 수 있을 것이다라는 가정을 가지고 본 연구가 수행되었다.


2. GPT: Unsupervised pre-training
GPT는 기존 트랜스포머 구조에서 인코더를 제외하고 디코더만 사용한다. 구체적으로, 디코더에서 'Encoder-Decoder attention layer'가 제거된 버전을 활용한다.
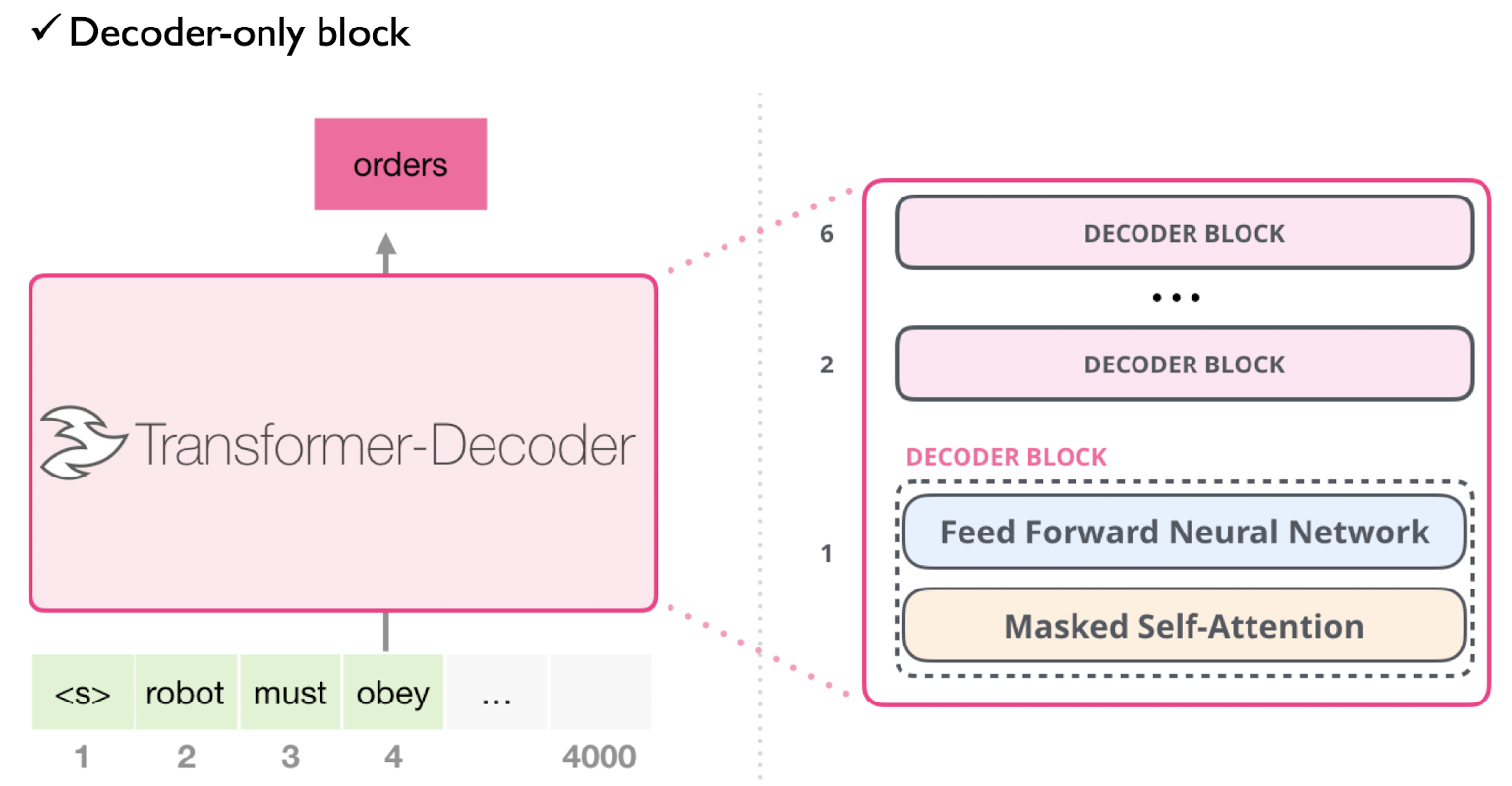
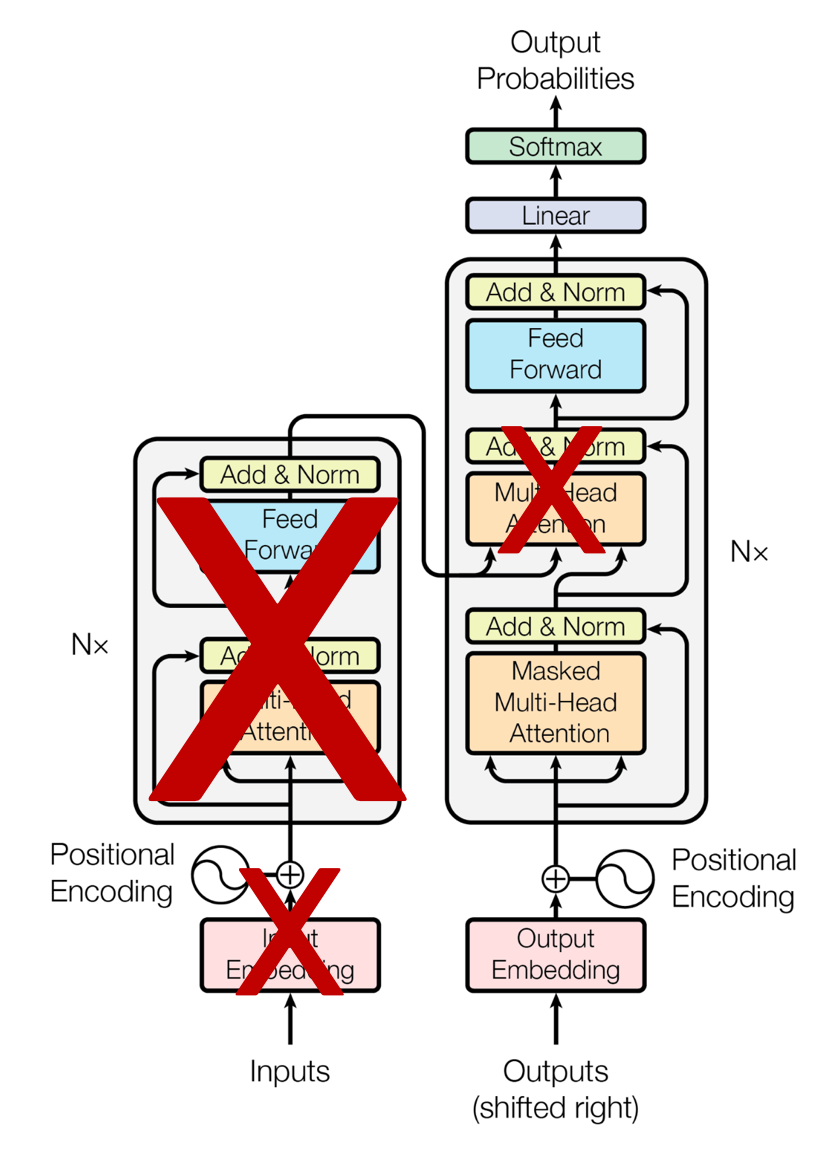
3. 학습데이터
- Pre-training 단계에서 사용한 데이터 종류
- BookCorpus

- 1 Billion Word Language Model Benchmark (used by ELMO)
- Task-specific 단계에서 사용한 데이터 종류

GPT-2: Language Models are Unsupervised Multitask Learners
GPT-2는 GPT-1보다 모델 크기(파라미터 수 기준)를 10배 키웠다. 그리고 GPT-1은 바이트 페어 인코딩(BPE)을 사용하는데, GPT2에서는 바이트 단위 바이트 페어 인코딩(BBPE)을 사용한다.
GPT-2는 특별히 새로운 아키텍처가 아니며, 트랜스포머 구조에서 디코더만 사용한 구조이다. 그러나, GPT-1에 비해서 훨씬 더 많은 대용량 데이터 셋(40GB, Web Text)으로 학습되었다는 차이점이 있다.
1. GPT-2 Architecture
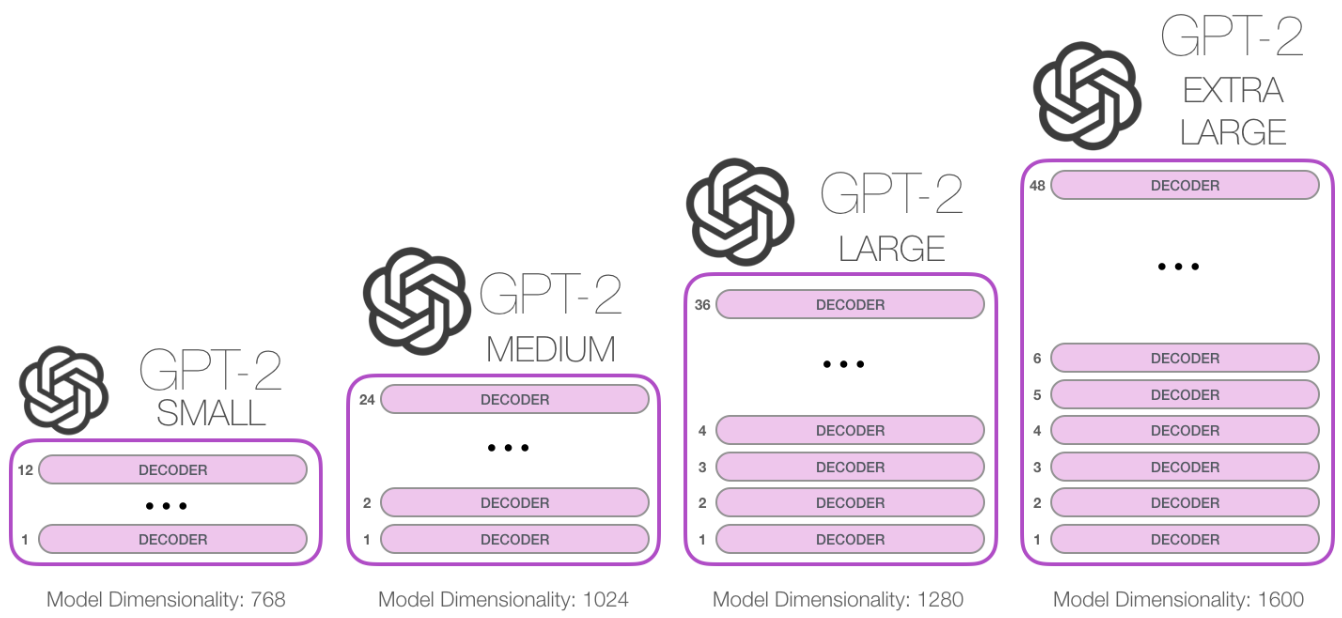
2. GPT-2와 BERT의 주요 차이점
GPT-2는 각 토큰이(Output) 생성된 후 해당 토큰이 입력 시퀀스에 추가되는 구조(Auto-regressive)이나 BERT는 그렇지 않다.

3. GPT-2 추론 단계
GPT-2의 추론 단계에서는 이전 단계의 출력을 입력 시퀀스에 추가하고 모델이 다음 예측을 수행 하도록 한다. 그리고, 학습을 시키는 것이 아니기 때문에 추론 당시의 경로만 활성화 되며 이전 단계의 토큰을 재해석하지(즉, 가중치를 조정하는 등의 학습을 시키거나) 않는다.


GPT-3: Language Models are Few Shot Learners
모델 구조면에서 GPT-3가 GPT-1과 GPT-2와 크게 달라진 것은 없으며, 모델의 크기가 GPT-2의 116배로 커졌다. GPT-3가 커지면서 GPT-1과 GPT-2에는 없던 능력이 생겼는데, 다운스트림 태스크에 맞게 모델을 파인튜닝 하지 않아도 해당 태스크를 바로 수행할 수 있는 것이다. 즉, 모델 업데이트 없이도 예제 몇 개만 주거나 전혀 주지 않아도 여러 태스크를 수행할 수 있다.
* 현재 GPT-3는 Pretrained 된 모델을 제공하는 것이 아니라 API 형태로 제공하여 쓴 만큼 과금을 하는 구조

1. 기존 NLP task 모델의 문제점
- Limitations:
- Pratrained Language Model(PLM)을 활용한 파인튜닝을 통해 특정 태스크에만 활용되는 아키텍처 구현의 필요성을 제거하였다다만, PLM이 다양한 태스크에 활용될 수 있다고 하더라도, 여전히 특정 태스크별 데이터 세트와 파인튜닝이 필요하다.
- Removing this limitation would be desirable because
- 새로운 태스크 학습을 위한 대규모의 레이블 된 데이터 세트가 필요하지 않게 되므로 언어 모델의 활용 가능성을 높일 수 있다.
- 인간은 언어와 관련된 태스크를 수행할 때 학습을 위한 대량의 데이터 셋을 필요로하지 않는다.
2. Training Cost

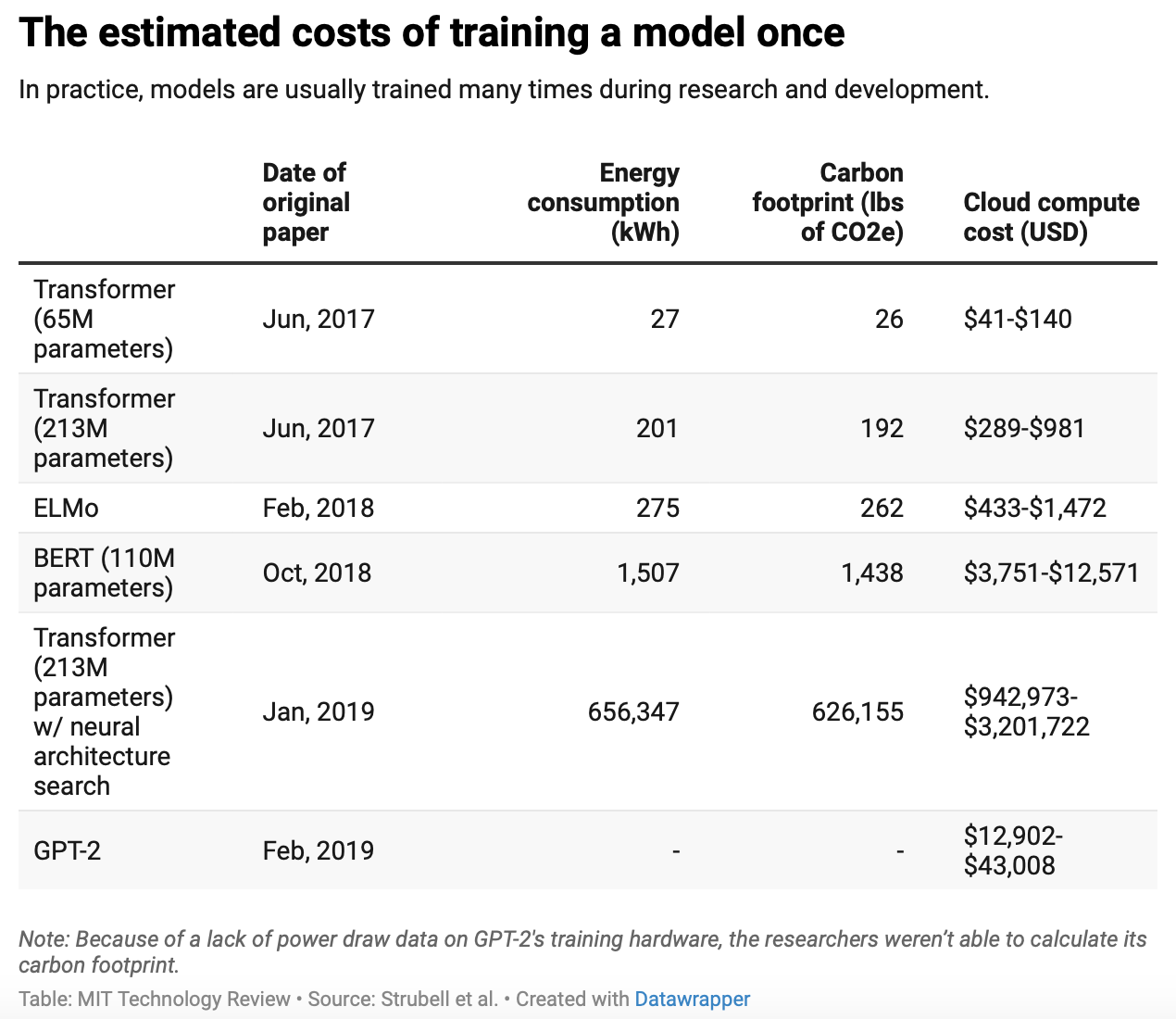
3. GPT-3 Architecture
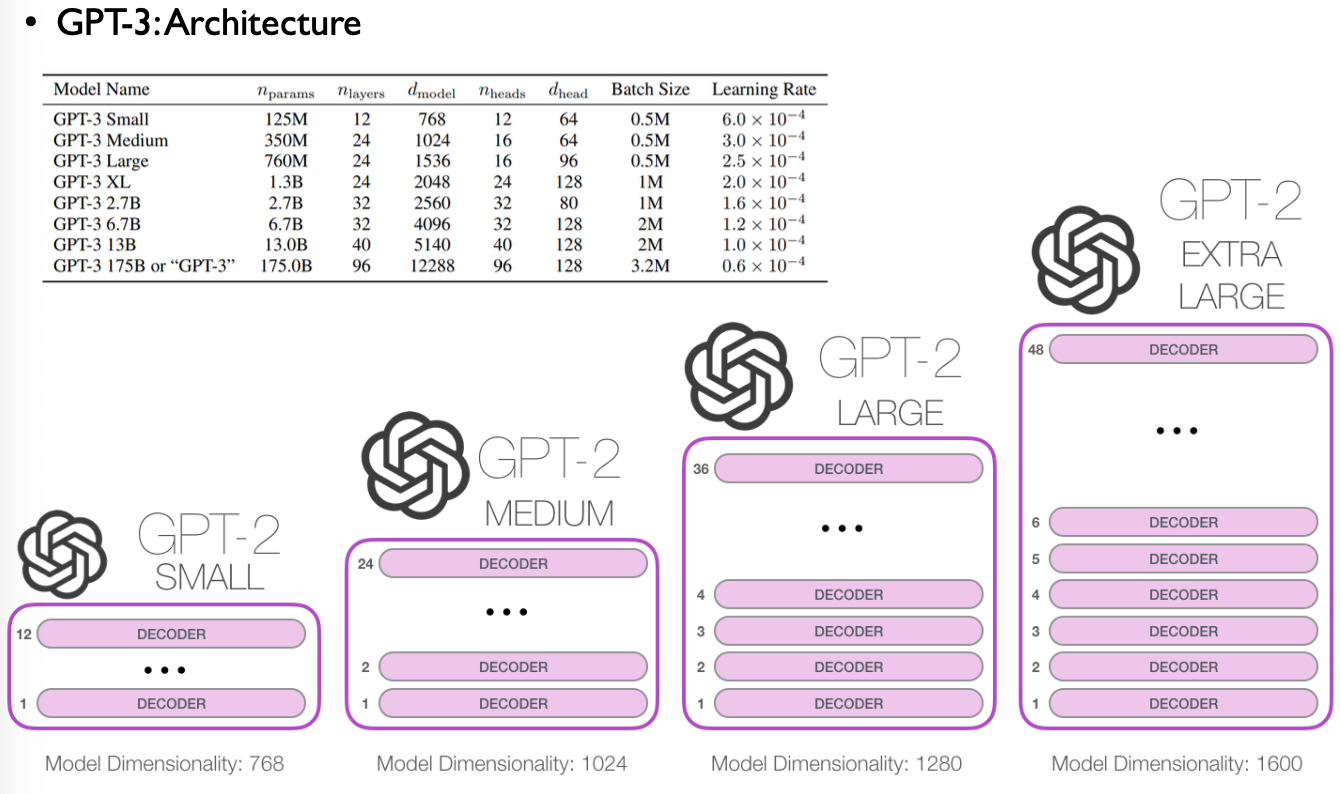
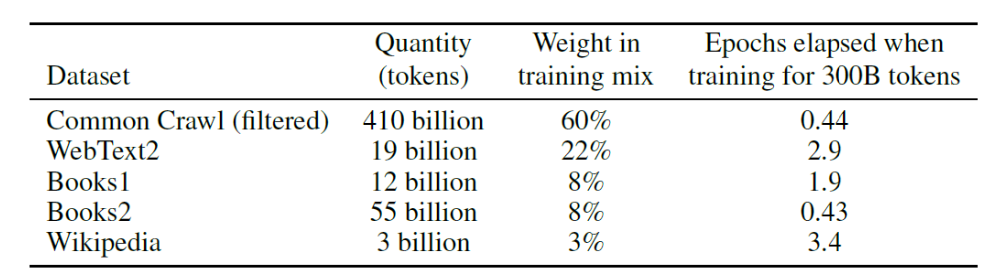
4. Training datasets
5. GPT-3 Approach
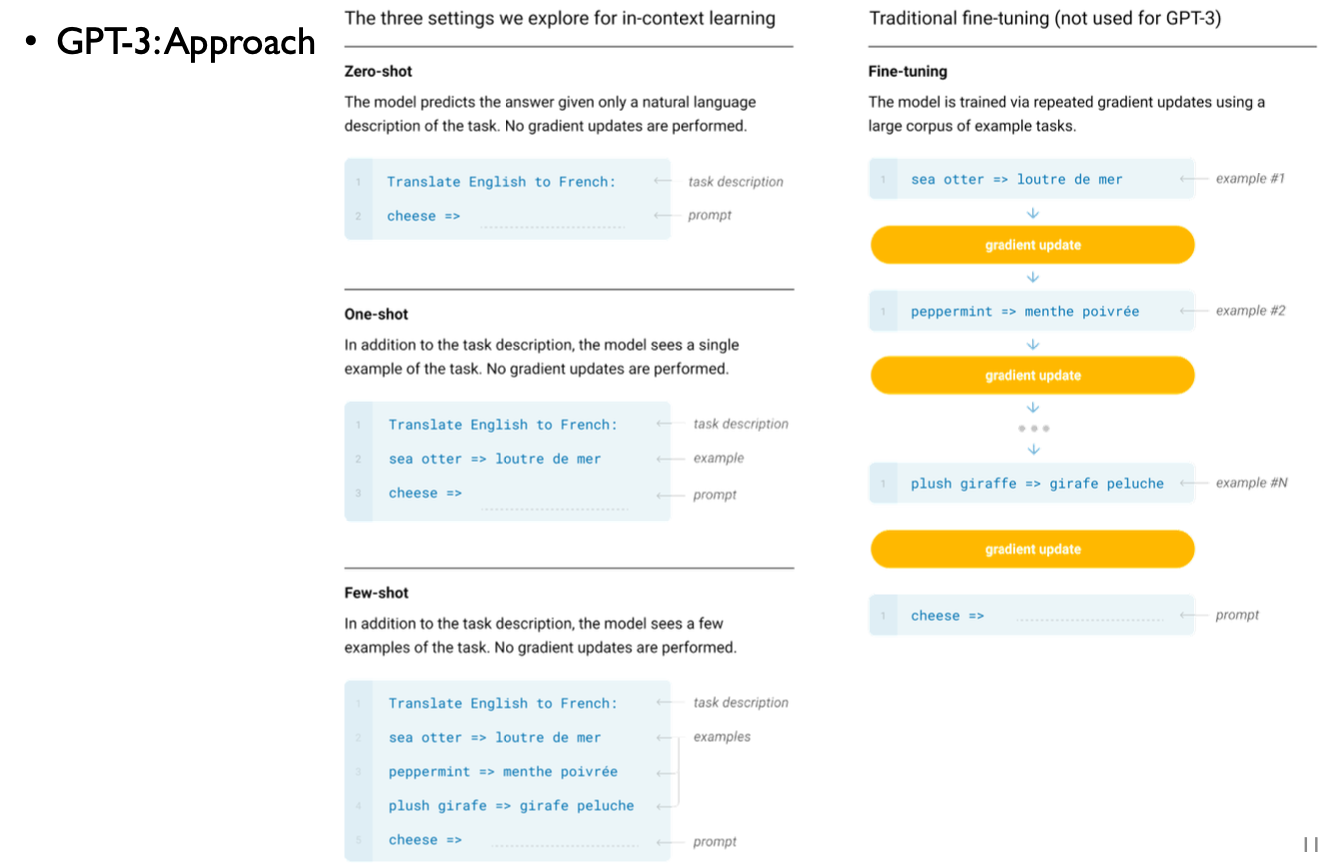
| 파인튜닝 (fine-tuning) |
다운스트림 태스크 데이터 전체를 사용. 다운스트림 데이터에 맞게 모델 전체를 업데이트 | |
| 프롬프트 튜닝 (prompt tuning) |
다운스트림 태스크 데이터 전체를 사용. 다운스트림 데이터에 맞게 모델 일부만 업데이트 | |
| 인컨텍스트 러닝 (in-context learning) |
다운스트림 태스크 데이터의 일부만 사용. 모델을 업데이트하지 않는다. | |
| 제로샷 러닝 (zero-shot learning) |
다운스트림 태스크 데이터를 전혀 사용하지 않는다. 모델이 바로 다운스트림 태스크를 수행 | |
| 원샷 러닝 (one-shot learning) |
다운스트림 태스크 데이터를 1건만 사용. 모델은 1건의 데이터가 어떻게 수행되는지 참고한 뒤 다운스트림 태스크를 수행 | |
| 퓨샷 러닝 (few-shot learning) |
다운스트림 태스크 데이터를 몇 건만 사용. 모델은 몇 건의 데이터가 어떻게 수행되는지 참고한 뒤 바로 다운스트림 태스크를 수행 | |
6. Broader Impacts: Misuse of language models
논문의 저자들은 언어 모델이 아직 완벽하지 않아 잘못된 의도를 가지고 활용 되었을 경우 충분히 사회적으로 큰 영향력을 끼칠 수 있다고 판단하여 이부분에 대해(잘못된 사용 관례에 대해) 아래와 같이 언급을 하고 있음
- Misinformation, spam, phishing, abuse of legal and governmental processes, fraudulent academic essay writing, social engineering pretexting, Fairness, Bias
6.1 Fairness, Bias, and Representations
저자들이 만든 모델이 정말로 특정한 집단에 대해 편향적인 사고방식을 가지고 있는지(편향된 Output을 생성해 내는지) 여러 실험을 통해 확인
예) Frequently answered words after
▪ "He was very” or “She was very”
▪ “She would be described as” or “He would be described as"

참고: MIT 테크놀로지 리뷰에 유출된 게브루의 연구보고서에 따르면 구글이 갖고 있는 대규모 언어 신경망 모델의 문제점은 크게 네 가지
- 첫째, 대규모 언어처리 인공지능 모델은 엄청난 전력소모를 유발해 지구온난화에 영향을 미침
- 둘째, 대규모 언어처리 인공지능 모델은 방대한 데이터들을 학습하는데 그 중에 인종차별, 성차별적 언어들이 섞이면서 인공지능이 잘못된 언어를 학습할 위험 있음
- 셋째, 현재 대규모 언어처리 인공지능 모델은 인간의 언어를 이해하지 못하면서 흉내내는 것에 집중하고 있음. 이게 인기를 끌고 사람들에게 많이 이용되면서 구글의 인공지능 연구 또한 이 쪽으로 집중되고 있지만, 사실 사람들에게 더 필요한 것은 사람의 언어를 진짜로 이해하고, 보다 작은 데이터라도 잘 학습하는 인공지능일 수 있음. 이런 쪽에 대한 연구는 관심을 받지 못하고 있다는 사실이 큰 위험
- 넷째, 대규모 언어처리 인공지능은 인간을 너무 흡사하게 흉내낼 수 있기 때문에 가짜뉴스, 딥페이크 등과 같은 곳에 응용될 수 있음
7. Energy Usage:
오픈AI가 2020년 6월 공개한 범용 AI인 GPT-3는 학습 과정에서 기존 GPT-2 모델보다 100배 많은 컴퓨팅 리소스를 사용한다. 그 과정에서 소비하는 에너지와 탄소 배출량이 덴마크 가정 126가구의 연간 소비량 및 배출량과 맞먹는 것으로 알려졌다.
http://www.dt.co.kr/contents.html?article_no=2022021802109931650001
References:
[1] GPT-1, GPT-2, GPT-3, https://www.youtube.com/watch?v=o_Wl29aW5XM&t=667s, 고려대 강필성 교수 유튜브
[2] BERT와 GPT로 배우는 자연어 처리, 이지스 퍼블리닝, 이기창
'GPT > 개념정의' 카테고리의 다른 글
| GPT 다음 토큰 선택 알고리즘 (1) | 2022.11.05 |
|---|---|
| BERT(Bidirectional Encoder Representation from Transformer) (0) | 2022.10.25 |
| 트랜스포머(Transformer) (0) | 2022.04.24 |
| 서브워드 토크나이저(Subword Tokenizer) (0) | 2022.04.24 |
| 토큰화(Tokenization) (0) | 2022.04.22 |



